Lobiチームの長田です。
今回はLobiで使用しているデータベースの構成・運用について紹介します。
TL;DR
- メインのデータベースとしてMySQLを使用
- 一般的なmaster-slave構成
- HAProxyとMHAでDBのfailoverを自動化
- HAProxyでslaveへの接続を分散・死活監視
- MHAで障害時のfailover・ENIを付け替えてmaster切り替え
で、何が起こるの?
サービスが提供できなくなります。 ユーザーの認証情報等、サービス提供に必要不可欠なデータを管理しているため、一時的なサービス停止は免れません。 ユーザー体験的にもビジネス的にも、大変厳しい状態です。
この「一時的」な時間を可能な限り短くするために障害復旧の一次対応を自動化しています。 自動化のメリットとして、単純にサービス停止時間が短くなることはもちろん、 復旧処理を行う際の人的なエラーを未然に防ぐことで二次災害の可能性を減らすことができます。
それでは実際にLobiで採用されている自動化の手段について紹介していきましょう。
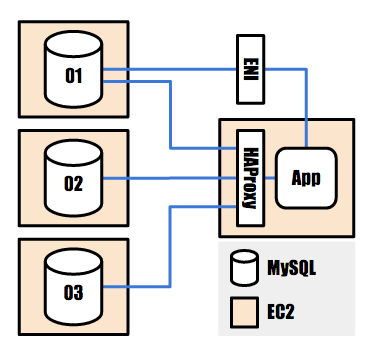
DB構成
LobiではサーバーインフラとしてAmazon Web Services(AWS)を利用しています。 Amazon EC2上でMySQLを動作させ、これをサービスのメインのデータベースとして使用しています。
一般的なmaster-slave構成を採用しており、 また一部のテーブルは水平分割されているため、master-slave構成が複数存在することになります。
アプリケーションからmasterへの接続はElastic Network Interface(ENI)を通して、 slaveへの接続はHAProxyを通して行っています。
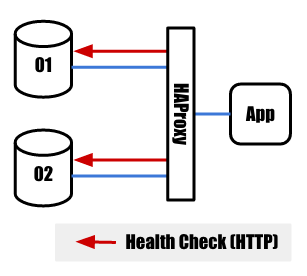
slave障害発生時
正常時は以下のようになっています。 図中では省略していますが、HAProxyとMySQLの間はHTTPで接続を受け付けMySQLのチェックを行うヘルスチェッカーが仲介しています。
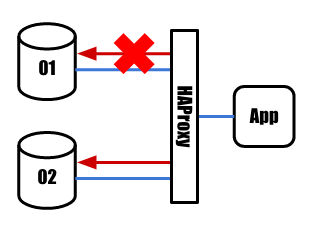
HAProxyが指定の間隔で行っているヘルスチェックが失敗すると、 そのホストには新規接続が回されなくなります。
アプリケーションはHAProxy通していれば常に正常なslaveに接続することができます。
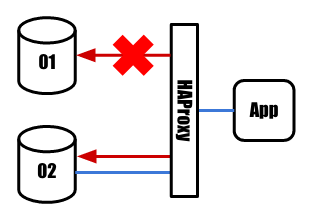
slaveは負荷的に余裕を持った台数が稼働しているため、このままでもサービス運用は可能です。 この状態からさらにslaveがダウンすると余剰分がなくなるため迅速にに新しいslaveを追加する必要があります。 HAProxyによるfailoverはあくまでも一次対応の自動化です。
HAProxyにはmasterを含めた全てのデータベースがserverとして定義されています。 言い換えれば、HAProxyはどのデータベースがmasterかは感知しません。 ヘルスチェックを行う際にmasterかどうかを確認し、masterであればチェックに失敗するようにしています。 ヘルスチェックに失敗したserverには接続が発生しないため、masterはslaveとして接続を受けることはありません。
# HAProxyの設定例
listen mysql-slave
bind 0.0.0.0:3307
mode tcp
balance roundrobin
# MySQLが起動しているインスタンスの指定したポート(この例では13307番)にhttpでヘルスチェックをかける
option httpchk
# db01はmasterだがヘルスチェックが失敗するようになっているのでslaveへの接続が振り分けられることはない
server db01 db-server01:3306 weight 100 check port 13307 inter 5000 rise 3 fall 3
# アプリケーションからの接続は以下の2台に振り分けられる
server db02 db-server02:3306 weight 100 check port 13307 inter 5000 rise 3 fall 3
server db03 db-server03:3306 weight 100 check port 13307 inter 5000 rise 3 fall 3
DBホストに常駐しているヘルスチェッカを手動でダウンさせることで、安全にslaveを切り離すことができます。 ホストであるEC2インスタンスのScheduled Reboot対応(つらい)や、不具合発生時の調査などに利用できます。
httpによるヘルスチェックについては以下を参照ください。
master障害発生時
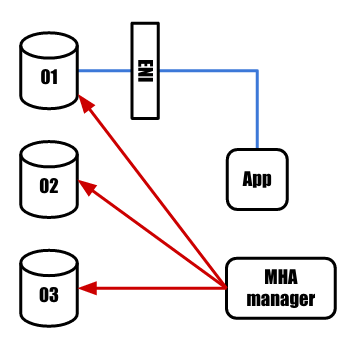
MHA managerが各master候補を監視しています。 この図ではDB01がmaster、02・03はslaveとして稼働しています。
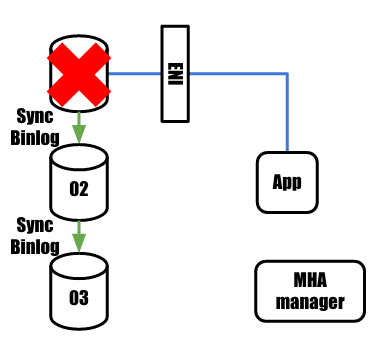
masterで障害が検知されると、MHA nodeによるbinlogの同期が行われます。
binlogの同期が完了すると、ENIが新しいmasterに付け替える処理が行われます。 アプリケーションから見ると接続先は変わりません。
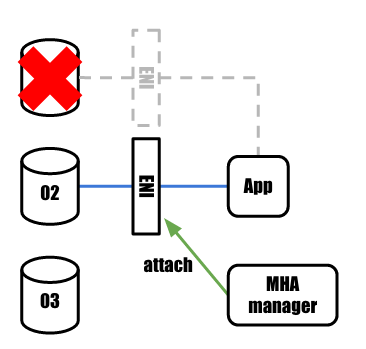
もともとslaveとして稼働していたDB02ですが、 masterとして稼働し始めた時点でHAProxy用のヘルスチェックが失敗するようになり、 前述のslave障害発生時と同様にslaveとしての新規接続は振り分けられなくなります。
ENIの付け替えにはMHA::AWSを使用しています。 MHA::AWSは弊社藤原作のfailover支援ツールです。 詳しくは以下の記事を参照ください。
MHAのmaster_ip_failover_scriptにMHA::AWSが提供するコマンドを設定することで、
failover後にENIが新masterにつけ変わるようになっています。
slaveからmasterに役割が変わることによってHAProxy用のヘルスチェックが失敗するようになり、
slaveへの接続は新masterを除いた各slaveに振り分けられるようになります。
これによりアプリケーションの変更をすること無くmasterデータベースのfailoverを行うことができます。
以下はMHA managerの設定例です。
[server default]
secondary_check_script=masterha_secondary_check -s some_host --user=root --master_host=db-master
master_ip_failover_script=mhaws master_ip_failover --interface_id=eni-123*****
master_ip_online_change_script=mhaws master_ip_online_change --interface_id=eni-123*****
shutdown_script=mhaws shutdown --interface_id=eni-123*****
[server1]
hostname=db-01
candidate_master=1
[server2]
hostname=db-02
candidate_master=1
[server3]
hostname=db-03
candidate_master=1
MHAそのものについてはMHAのドキュメントを参照ください。
自動化最高!
影響範囲の大きい操作が自動化されていると安心感が段違いです。 導入には検証も含めてそれなりのコストがかかりますが、その価値は充分にあります。 便利なツールを提供してくれている作者の方々に感謝 :pray:
次回
Lobiで実際に使用しているgo製アプリ・ツールについて紹介します。