このエントリはtech.kayac.com Advent Calendar 2012 6日目の記事です。
テーマは「私の中のマイイノベーション 2012」
2日目の記事を見て、条件反射的に僕もおっぱいについての記事を書こうと思いましたが、 産まれた子供が「お父さんはいつもおっぱいのことばっかり考えていて気持ち悪い」と思ってしまったらと思うと、こんな危険な橋を渡るわけには行かず、 実際いつもおっぱいのことばかり考えているんですけど、おっぱいのことなんて全然興味ないです。
息子よ、父さんはいつだってまじめに働いているよ!
というわけで今年作った"まじめな"ツールのMySQL::Sharding::Clientを自画自賛したいと思います。
MySQL::Sharding::Client
MySQL::Sharding::Clientは一言で言うと「ShardingしてつかっているMySQL群を扱いやすくするツール」です
Shardingとは
僕のプロジェクトでは、DBをSharding(水平分割)しています。
Shardingは非常に多くのトラフィックやデータが見込めるサービス(またはそうなったサービス)で、1台(セット)のDBでまかないきれなくなったときに、テーブル毎水平に分割する手法です。
僕の担当しているサービスでは、下図のように全く同じスキーマ群を持つ複数のshard群に対して、masterDBで管理しているmappingテーブルを用いてユーザー毎に使用するshardを振り分けて分散する手法を使っています。
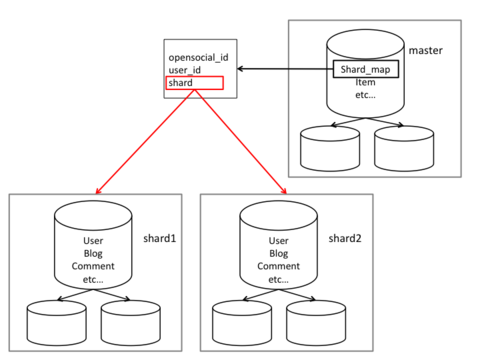
こうすることによりユーザーが増えても比較的安心ですし、シャードを追加するのも比較的容易にできるようになります。 しかし、この手法は諸刃の剣でして安心を得る変わりにあまりにも多くの便利なものを失うことになります。
Shardingによって失うこと
- JOIN
- AUTO_INCREMENT
- 全体に体するSUMやCOUNT
- メンテナンス性、開発難易度の飛躍的な上昇
などなど、とにかくShardingは辛い
JOINとAUTO_INCREMENTが使えない
JOINに関してはマスター系DBと物理的に別れているのでどうあがいても使うことができません。
AUTO_INCREMENTを利用してしまうと上図におけるShard1とShard2で同じ数字を割り振ってしまうためサービス全体を通して一意ではなくなってしまいます。 そこで、上図におけるmasterDBの中に採番テーブルを作り下記のように利用します
CREATE TABLE sequense (
id BIGINT unsigned NOT NULL
);
UPDATE sequense SET id = LAST_INSERT_ID(id+1);
SELECT LAST_INSERT_ID();
クソ面倒くさいですね
SELECTが遠回り
ユーザー情報の閲覧をする為には一度mappingテーブルからユーザーの属しているShardを特定するという面倒くさい作業をする必要があります。
集計クエリを実行しようとすると、物理的に2つのDBに分けてデータが入っているため、例えば上記の場合でcommentの件数等を集計しようとした場合、2つのデータに対してそれぞれクエリを実行してから、 手元で再集計するようなことが必要になります。
これが超面倒くさいのです。
MySQL::Sharding::Clientで解決できること
JOINやAUTO_INCREMENTについては開発時に時間がかかり面倒がふえるだけで、乗り越えてしまえば忘れることができますが、 運用して行く中でSELECTが面倒くさいというのは正直致命的です。 ShardingをしているだけでShardingをしていないときに比べて運用コストは3倍と行っても過言ではないくらいかかります。
これを普通に近い労力にしてくれるのがMySQL::Sharding::Clientです。
MySQL::Sharding::Clientを使うと、全てのDBがさも一つのデータベースかのように一部のSELECTクエリを扱うことができます。
例えばs1とs2という2つのDBに下記のようなスキーマのテーブルが入っているとします。
CREATE TABLE `comment` (
blog_id INT NOT NULL,
value VARCHAR(255),
INDEX blog_id_idx(blog_id)
);
それぞれにクエリ下記のような流れでクエリを打つと
mysql> use s1
mysql> select * from comment;
+---------+-------+
| blog_id | value |
+---------+-------+
| 1 | hoge |
| 1 | fuga |
| 1 | foo |
+---------+-------+
3 rows in set (0.00 sec)
mysql> select count(*) from comment;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from comment where blog_id = 1;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.01 sec)
mysql> use s2
mysql> select * from comment;
+---------+-------+
| blog_id | value |
+---------+-------+
| 2 | foo |
| 2 | baa |
+---------+-------+
2 rows in set (0.00 sec)
mysql> select count(*) from comment;
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from comment where blog_id = 1;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
これに対してMySQL::Sharding::Clientをつかってみます
$ shard_prompt
s2 --> connect --> OK
s1 --> connect --> OK
sharding> select * from comment;
+---------+-------+---------+
| blog_id | value | claster |
+---------+-------+---------+
| 1 | hoge | s1 |
| 1 | fuga | s1 |
| 1 | foo | s1 |
| 2 | foo | s2 |
| 2 | baa | s2 |
+---------+-------+---------+
s2: (0.000911 sec)
s1: (0.001077 sec)
sharding> select count(*) from comment;
+----------+---------+
| count(*) | claster |
+----------+---------+
| 5 | s1,s2 |
+----------+---------+
s2: (0.002047 sec)
s1: (0.000267 sec)
sharding> select count(*) from comment where blog_id = 1;
+----------+---------+
| count(*) | claster |
+----------+---------+
| 3 | s1,s2 |
+----------+---------+
s2: (0.002696 sec)
s1: (0.000436 sec)
このように複数のDBをまとめて扱うことができます。
まじイノベーティブ!!!!
残念ながら、弊社の大多数を占めるShardingをしていないチームのエンジニアにいかにこれがイノベーティブかを説明してもリアクションが薄いので悔しい思いをしてきましたが、 きっと沢山いるShardingのせいで髪が薄くなったり、貧乏揺すりが止まらなくなったり、変な声を上げたくなるくらいイライラしている辛い思いをしているどこかの誰かの手助けになればと思っております。
ちなみに、これ便利だからといって運用以外のアプリのコードに入れるとShardingした意味が無くなってしまうので本当にやめてください。 あとCOUNT,SUM,MAX,MINあたりはよく使うので実装していますが、AVGは実装していないのでpull reqしてくれたらとっても嬉しいです。
Shardingはマジでしたくないです。 でもShardingせざる得なくなるようなサービスをつくりたいです。
明日はCoffeeが旨いと評判のid:SOMTDが超イカしたイノベーティブをお届けしてくれると思います