こんにちは、グループ情報部の@mashiikeです。
2026年4月9日に、BigQuery の新機能「BigQuery Graph」が Preview になりました。
BigQuery Graph は、BigQuery 上のテーブルデータをグラフとしてモデリングし、ISO GQL 標準に準拠した Graph Query Language で分析できる機能です。
ノードとエッジのテーブルさえ用意すれば CREATE PROPERTY GRAPH でグラフが定義でき、GQL で関係性を辿れるようになります。
身近なグラフデータと言えば、dbt のリネージグラフだなと思い、PoC としてパッケージを書いてみました。
dbt のリネージ情報について
dbt をお使いの方はご存知だと思いますが、dbt は compile 時にプロジェクト全体の DAG(有向非巡回グラフ)の情報を持っています。
Jinja のコンテキスト変数 graph.nodes と graph.sources を通じて、どのモデルがどのソースやモデルに依存しているかが全てわかります。
最近は MCP で BigQuery へアクセスできるので、リネージの情報が BigQuery 上にあれば、わざわざ Claude 等にリポジトリを渡さなくても依存関係を調べられて便利そうですよね。
仕組み
dbt-bigquery-lineage-sync は、2つのコンポーネントで構成されています。
nodes と edges のモデル
nodes と edges というモデルを dbt build すると、dbt の manifest にあるリネージ情報をマクロで参照して BigQuery に incremental model として保存します。
profile_name ごとに分けて保存しているのは、dbt で複数環境に分けて開発する場合は profile_name で環境を分けることが多いためです。
create_or_replace_lineage_graph マクロ
nodes と edges を保存するだけでも有用ですが、create_or_replace_lineage_graph マクロを使うことで Property Graph を定義でき、今回の Preview 機能である GQL を使ってリネージを調べられるようになります。
使い方
セットアップ
packages.yml に追加して dbt deps するだけです。
packages: - git: "https://github.com/mashiike/dbt-bigquery-lineage-sync" revision: v0.0.0
テーブルの作成とグラフの定義
# 1. ノードとエッジのテーブルを作成 dbt build --select dbt_bigquery_lineage_sync # 2. Property Graph を作成 dbt run-operation create_or_replace_lineage_graph
これだけです。2段階なのは、Property Graph の DDL が dbt の標準的な materialization ではないため run-operation で実行する必要があるからです。
GQL で調べてみる
グラフができたら、GQL でリネージを調べてみましょう。
モデルの一覧を出す:
GRAPH `infra-dev-281205.dbt_lineage`.`graph` MATCH (n:DbtNode) WHERE n.resource_type = "model" RETURN n.name, n.materialized ORDER BY n.name

特定モデルの直接の上流を調べる:
GRAPH `infra-dev-281205.dbt_lineage`.`graph` MATCH (upstream:DbtNode)-[e:DependsOn]->(downstream:DbtNode) WHERE downstream.name = "orders" RETURN upstream.name, upstream.resource_type

3ホップ先まで辿る:
GRAPH `infra-dev-281205.dbt_lineage`.`graph` MATCH (src:DbtNode)-[:DependsOn]->{1,3}(dst:DbtNode) WHERE dst.name = "customers" AND dst.resource_type = "model" RETURN src.name, src.resource_type
この -[:DependsOn]->{1,3} という書き方で「1〜3ホップの範囲で DependsOn エッジを辿る」という意味になります。

「このソースを変更したら影響範囲どこまで?」みたいな問いに、SQL の延長でサクッと答えが出せるのはなかなか便利です。
ノートブックで可視化する:
BigQuery Studio のノートブックでは %%bigquery --graph マジックコマンドを使うと、GQL の結果をグラフとして可視化できます。
%%bigquery --graph GRAPH `infra-dev-281205.dbt_lineage`.`graph` MATCH p = ((src:DbtNode)-[:DependsOn]->(dst:DbtNode)) WHERE dst.name = "customers" RETURN TO_JSON(p) AS path

この GRAPH 構文を人間が覚える必要があるのか?
GQL のクエリ例をいくつか紹介しましたが、正直なところこの構文を人間が毎回書くのかというと微妙なところです。
冒頭で「MCP で BigQuery にアクセスできるなら便利そう」と書きましたが、MCP Toolbox for Databases を使えば Claude Code から BigQuery に直接アクセスできます。
.mcp.json に以下のように設定するだけです。
{ "mcpServers": { "bigquery": { "command": ".bin/toolbox", "args": [ "--prebuilt", "bigquery", "--stdio" ], "env": { "BIGQUERY_PROJECT": "${BIGQUERY_PROJECT}" } } } }
さらに、リポジトリにはサンプルの Claude Code スキルも用意しています。
このスキルを入れておけば、「customers モデルのリネージを可視化してほしい」と聞くだけで GQL を組み立てて実行してくれます。

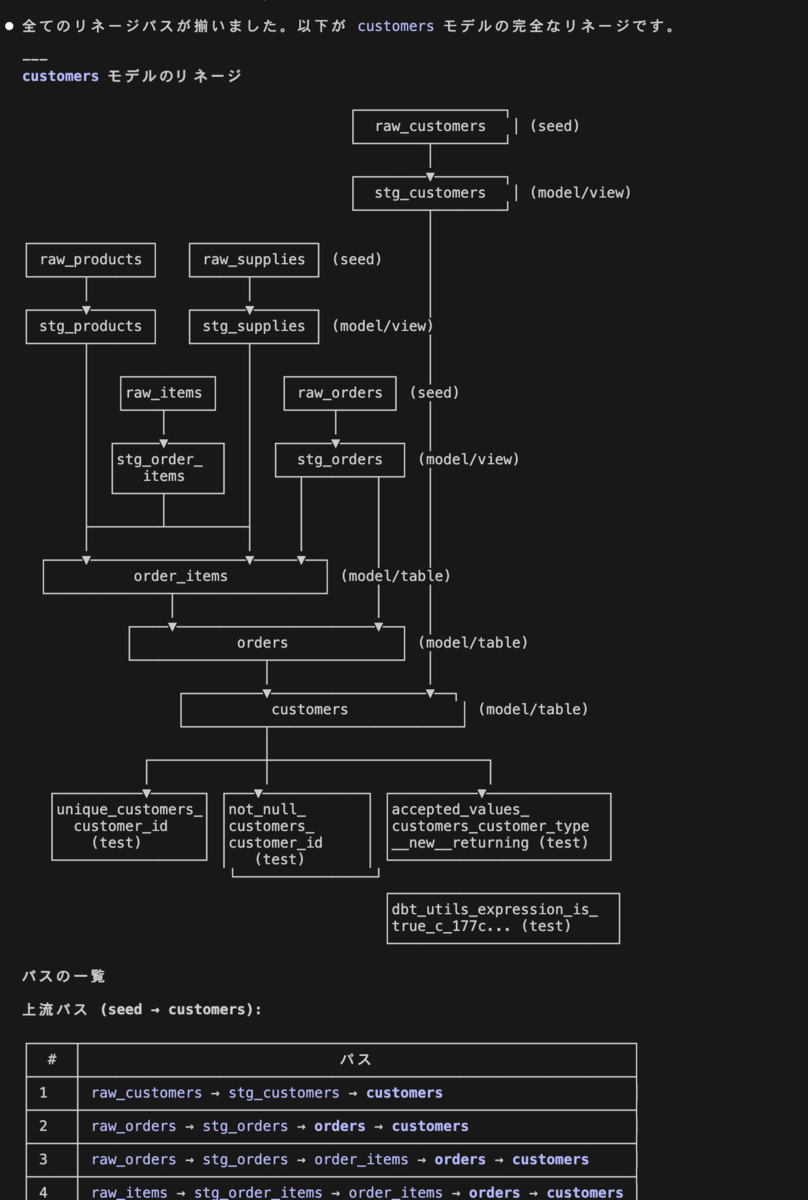
人間が GRAPH 構文を覚える必要はありません。
まとめ
BigQuery Graph が Preview になったので、dbt のリネージ情報を Property Graph として載せて GQL で調べられるようにする PoC パッケージを作ってみました。
やってみた感想としては、BigQuery Graph と dbt のリネージは相性が良いです。
「このソースを変えたら影響範囲は?」「このモデルの上流3段を辿りたい」みたいなクエリが、BigQuery の中だけで SQL の延長として書けるのは楽です。
グラフデータベースを別途用意する必要がないのも嬉しいですね。
まだ PoC なので粗い部分はありますが、興味のある方はリポジトリを試してみてください。
BigQuery Graph がGAになるのが楽しみです。
カヤックでは、データパイプラインを調べるのが好きなエンジニアも募集しています!
Generated with Claude Code