SREチームの長田です。
今回はカヤックで運用している「まちのコイン」というプロダクトのアプリケーション基盤を Amazon EKS(以下EKS)からAmazon ECS(以下ECS)に移行したはなしをします。
まちのコインとは
まちのコインはカヤックが運営している、デジタル地域通貨を使ってその地域のコミュニティを活性化させるサービスです。 2019年11月から実証実験を開始し、翌年2月から正式リリースされました。 2022年9月現在、20の地域に導入されています。
一般ユーザーが使用するクライアントアプリと、導入地域の運営団体が使用するブラウザ用の管理画面、 それらにAPIを提供するRailsサーバーアプリがあります。 データベースはAmazon Aurora PostgreSQL、 その他AWSのマネージドサービスを組み合わせたオーソドックスな構成です。 他にも運用監視用途の小さなアプリケーションがECSやAWS Lambdaなどで稼働していますが、 今回の趣旨とは外れますので説明は割愛させていただきます。

まちのコインには開発当初から昨年5月頃から筆者が担当するようになるまで、SREチームの手が入っていませんでした。
なぜEKSからECSに移行したのか
EKSで運用し続けるメリットよりも、デメリットのほうが大きいと判断したためです。
EKSを使い続ける理由がなくなった
EKSを選択した理由として、当初はカヤックではシステムの開発のみを行い運用までは行わない予定だった、というものがあったようです。 システムを運用するプラットフォームに汎用性を持たせるために、AWSに依存しないKubernetes(以下k8s)を採用したとのことでした。
しかし、結局はカヤックで運用することになり、開発時に使用していたAWSを継続利用することになったため、 「EKSを使い続ける理由」がなくなってしまいました。
社内ではECSの利用が一般的
カヤックで運用・開発している自社プロダクトは、ほとんどがECSを採用しています。 運用中の自社プロダクトではECSとAWSのマネージドサービスを組み合わせた構成で十分であったこと、 また社内に先行事例が豊富にあるため新規プロダクトでも採用しやすいという理由があります。 そのため、ECS関連のツールやノウハウは豊富にある一方、EKSに関するものは皆無でした。
EKS関連でなにか問題が発生した場合も社内の事例に当たることができませんし、 ツールを開発してもまちのコインの開発運用チームにしか恩恵がありません。
また、エンジニアが異動してきた際にもEKSの使い方をイチから学習し直す必要がありました。 ECSとの対応づけで個々の用語の意味は推測できるものの、微妙に勝手や使い方が異なる部分を一つ一つ確認していく必要がありました。

定期的なアップグレードの存在
EKSはマネージドなk8sということで、そのサポートバージョンはk8sのリリースサイクルに依存します。 このため、EKSを継続的に利用していくためには毎年アップグレード作業が発生します。
EKSの自動更新に任せてしまうという手もなくはないですが、非互換な変更や挙動の変化を踏み抜くリスクを考えると 結局は事前の移行テストと、新バージョンでの新クラスタ作成の後に切り替え・問題発生時のロールバックを計画することになるのではないでしょうか。 このコストはなかなか無視できるものではありません。
ECSにもプラットフォームバージョンのアップグレードは存在しますが、 少なくともAWS Fargateを使用している限りはクラスタの作り直しは必要なく、 ECS Serviceごとに対応することができます。
このタイミングでEKSからECSに移行し始めたのも、 EKSにおけるk8s 1.19のEoLが2022年6月末に迫っていたという理由からでした。
参考:
- Amazon EKS Kubenetes リリースカレンダー https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/kubernetes-versions.html#kubernetes-release-calendar
- Releases | Kubernetes https://kubernetes.io/releases/
ECSで十分
前述の通りアプリケーションはRailsで作られたAPIサーバーのみです。 これを動かすためだけにEKSを使用するのはオーバースペックであると判断しました。
前準備
アプリケーション実行環境の移行ということでそれなりに大きな変更を行うわけですが、その前にやっておきたいことがありました。 いままでSREチームが関わっていなかったということで、運用に関する作り込みが甘い部分を補強していきました。
監視
CloudWatchによる簡素なアラート設定のみだったので、Mackerelを導入しました。 CloudWatchでの監視を作り込むという手もありましたが、どうせ作り込むなら社内で一般的に使用しているツールを使おうということでMackerelの導入を選択しました。
Infrstructure as Code(IaC)
開発当初にCloudFormationを使用していたということでしたが、最近はメンテナンスされていないということだったので、 Terraformを導入しました。 こちらも社内で一般的に使用されているツールという理由から選択しました。
k8sが管理するリソースと、そうでないものを切り分けつつ、ECS移行に必要なリソースを定義していきました。
ステージング環境
アプリケーションのQAに使っている環境はあったのですが、インフラリソースも含めた動作確認を行う環境はありませんでした。 ECS移行にあたり、関連リソースの動作確認が必須になったため、移行に先んじて環境を用意しました。
新しい環境を立ち上げるための、アプリケーションから参照する初期データ類も合わせて用意しました *1。
EKSからECSに移行した際のポイント
アプリケーション本体はすでにコンテナ化されていたため、これをECS上で動かすための調整と、関連するマネージドサービスの整備が主となりました。
定期実行処理
定期実行処理にはk8sのcronjobを使用していたため、これを代替する仕組みとして 以下のマネージドサービスを組み合わせた定期実行処理の仕組みを構築しました。
- Amazon EventBridge: ルールによるjobのスケジューリング。 実行するべきrake taskを指定してStep Functionsのstate machineを起動
- AWS Step Functions: ECS run Taskの実行。 失敗時のリトライと、リトライ上限を超えた場合のSNS通知
- ECS run Task: 定期実行処理の本体
ECS run Taskの部分についてはより実行コストの低いAWS Lambdaを採用する案もありましたが、 実行時間がLambda functionの実行上限である15分を超えるjobが存在したため断念しました *2。
Step Functionsのstate machine管理にはカヤックのSREチームメンバーが開発したstefunnyを採用しました。 https://github.com/mashiike/stefunny
秘密情報の受け渡し
秘密情報のたぐいはAWS Secrets Managerで管理しています。
Railsアプリへの秘密情報の受け渡しにはKubernetes External Secretsを 使用していましたが、ECSに移行するにあたりECS Taskのsecrets参照に置き換えました。
また、環境変数経由で秘密情報を渡す場合とRailsアプリから直接Secrets Managerを読む場合が混在していたため、 環境変数経由の受け渡しに統一しました。
デプロイ
デプロイ用のECS Task上で所定のコマンドを実行する方式にしました。
まずEKSへのデプロイ方法についてインターフェイスの統一と簡略化を行い、その上でデプロイ処理をECS用のものに置き換えました。 予めインターフェイスの統一を行うことで、ECS移行後のデプロイ操作に混乱が生じにくいようにしました。
ECSへのデプロイには社内で利用実績があるecspressoを採用しました。 https://github.com/kayac/ecspresso
ダウンタイムを発生させない接続先切り替え
単純にダウンタイムを発生させたくないというのもありましたが、それ以上に一度にすべてをECS環境に切り替えることに不安があったため、 EKSとECSそれぞれで並行してアプリケーションを稼働させ、それらに配分するクライアントからのリクエスト比率を操作して様子を見るという方法を取りました。
リクエスト比率の操作にはAmazon Route53のweighted recordを使用しました。
まず移行先であるECS環境を用意しました。 この時点ではクライアントからECS環境へのリクエストはありません。
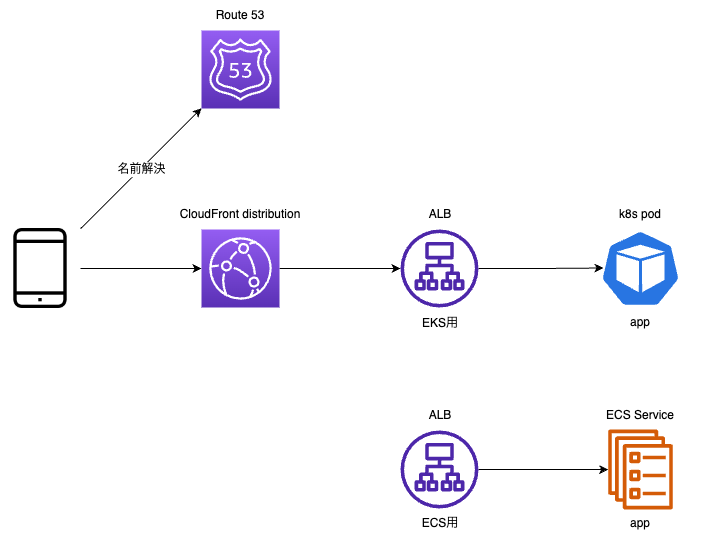
次にECS環境の動作確認のために、一部のリクエストをECS環境に回しました。 Route53 weighted recordの、ECS用ALBの比率を徐々に上げ、ECS Taskの負荷の変化を観察しました。

ECS環境の動作に問題ないことが確認できた後、Route53 weighted recordの比率をすべてCloudFrontに解決されるよう戻した後、 CloudFrontのOriginをECS用ALBに変更しました。

結果、誰にも気づかれることなくダウンタイムなくECS環境への切り替えが成功しました。
より慎重に動作確認を行うのであれば、ECS用ALBの前段にもCloudFrontを置いて動作を確認するべきでしょう。 しかし、CloudFrontにはdistribution間で重複した代替ドメインを設定できないという制約があります。
代替ドメインにワイルドカードを設定することでこの制約を回避する方法もありますが、 以下の理由から採用には至りませんでした。
- まちのコインには複数のCloudFront distributionが存在しているため、複数同時に動作確認を行おうとするとワイルドカードドメインが重複してしまう
- CloudFront distributionをひとつずつ動作確認していく時間的余裕がなかった
今回は動作確認として必要十分な結果が得られるであろうと判断し、 CloudFront distributionとALBのそれぞれリクエストを振り分けるという方法を取りました。
失敗談
一見すんなり完了したように見えますが、もちろん失敗もありました。
移行開発期間中の複数環境対応
移行のための開発期間中も、アプリケーションの開発は続いています。 移行開発ブランチとメインブランチとの差分が大きくなると、後のマージコストが大きくなります。 そのため、移行開発ブランチを要素ごとに細分化し、こまめにメインブランチに取り込むようにしていました。
本番環境との互換性は特に注意していたのですが、それとは別のQA環境での対応が疎かになることがありました。 アプリケーションのデプロイに関する設定がうまく切り分けられていなかったり、 アプリケーションの起動に必要な環境変数の設定漏れがあったり、という問題です。
QA用環境ということで開発チーム内にしか影響がない問題ではあったのですが、 それにより開発を妨げてしまったのは事実です。
「EKSからECSに移行した際のポイント」の「デプロイ」で述べたような、 インターフェイスの共通化 → 実装の変更 という手順を徹底できれば問題の発生をより少なくできたように思います。
時期尚早なドッグフーディング
移行開発期間の終盤で、動作確認として開発・運用メンバーからのリクエストのみECS環境に切り替えました *3。 クライアントアプリ用のAPIについては問題がなかったのですが、 管理画面用のAPIについては動作テストが不十分な部分があり、実際に管理画面を使用する運用メンバーの業務に支障をきたす場面がありました。
内部メンバーからのリクエストのみ切り替えた意図は、 「実際にクライアントアプリ・管理画面を使用した場合に問題が発生しないかどうかを確認する」ことでした。 そのため運用メンバーの操作による不具合発生は狙い通りではあったのですが、 「リリース前の不具合の発見」と「円滑な運用」のバランスが悪かった、あるいは運用メンバーとの合意形成が不十分であったと反省しています。
本番環境とステージング環境の差異
作成したステージング環境はECS移行後の状態となっていました。 本来であれば現行の本番環境に合わせてEKSで環境を構築し、ECSへの移行作業をそのまま再現できるようようにするべきでしょう。
そのため、全体を通しての移行操作リハーサルは行なえませんでした。 もちろん個々の操作については検証を行ってはいましたが、それでも実際に本番環境で移行を行った際にはいくつかの問題が発生しました *4。
プロダクトの価値を落とすリスクを減らすためにも、ぶっつけ本番のストレスを無くすためにも、 開発の初期段階からステージング環境を用意することを強くおすすめします。
ECSへの移行を終えて
EKSからECSへの移行に要した期間は、間に他の案件もはさみつつではありましたが、およそ1年でした。 大部分の期間は筆者一人で進めましたが、終盤の詰めの部分ではアプリケーションとのつなぎこみ担当としてサーバーサイドのエンジニアに、 他のチームとの調整役としてプロジェクトマネージャーにも参加してもらいました。 また、移行に関する変更はすべてGitHubのPull Requestとしてサーバーサイドメンバーにレビューしてもらいました。
使い慣れた構成ということで、移行後も目立った問題は発生していません。 なにか問題が発生したとしても、見るべき場所がわかっているので安心感があります。
EKS(k8s)でシステムを運用することに関しては個人的には興味があったのですが、総合的なコストを鑑みてECSに移行するという判断をしました。 移行に際してプロダクション環境として使用しているEKS(k8s)に触れる機会が得られ、 その上で「汎用性は高いが作り込みと覚悟が必要」「今のまちのコインにはオーバースペック」という考えを持てたことは、自分としては収穫だったように思います。
まちのコインの今後
まちのコインはまだまだ成長の余地があるプロダクトです。 その成長を妨げないための課題として、安全なオペレーションのための改善・システムの自動化・不要なコストの削減など、SREとしてできることが多くあります。 「適切なアプリケーション実行環境への移行」によって、それらの課題に取り組む地盤ができたと言えます。
カヤックのSREチームの目標である「SREチームの仕事をなくすこと」 に向けて日々前進している最中なのです。
まとめ
今回の移行プロジェクトを経て、要件・規模・環境にあった技術選定が重要であることを再認識しました。 ビジネスを鈍化させないために、状況に合わせて適切な選択をしていきたいですね (あと、長期運用するプロダクトには開発初期からSREを関わらせてくださいお願いします 🙏)。
*1: 受け継がれた秘伝のDBダンプファイルを取り込んで・・・というのはままある話なのではないでしょうか。 直後に開発環境のmirage化も控えていたため、 外部依存のないまっさらな初期データが必要だったという背景もあります
*2:15分以内に終了するjobについては部分的にLambdaで実行することも検討しています。
*3:今回はリクエスト元のIPアドレスを見て、開発・運用拠点のものであればECS環境に振り分けました。 恒常的に使用する場合は心許ない条件ですが、完全移行までの期間限定ということで実現コストがかからない方法を選択しました
*4:発生した問題の詳細については設定ミス等の小さな原因がほとんどでしたので割愛させていただきます