こんにちは!2021年技術部新卒研修を担当しました、秦です。社内ではがはくちゃん(5さい)と名乗っています。
2020年に引き続きオンラインベースで行われた技術部新卒研修ですが、今年は後半の部のキックオフとして社内CTFを実施しました。 昨年入社の身で大変僭越ながら、その作問・運営をさせていただいたのでその振り返りを書かせていただきます。
これからCTFの作問をするぞ〜‼でもなにをすればいいかわからないよ〜‼という2ヶ月前のわたしのような元気なエンジニアの方に届けば良いなと思っています(もしくは、エッ……カヤックって新卒研修でCTFなんかやるんだ……と思ってもらえたら良いですね)。
経緯
「今年の新卒研修担当には画伯を拉致します」
わたし「えっ?」
「画伯にはCTFを作ってもらおうとおもいます!」
わたし「えっ??」
「社内にCTF経験者特にいないから画伯だけが頼りです!」
わたし「えっ???」
今まで弊社で社内CTFを開催したという事例はなく、さらに社内のエンジニアのほとんどはCTF未経験者(名前は聞いたことある程度)ということだったのでワオ……という感じではありましたが、たのしそうだったので快諾させていただきました。ありがとうございます
問題の構想を練る
今回は社内CTFという形ではありますが、Webエンジニアの新卒研修なので問題はWebに絞りつつ全問Webだと疲れちゃうよな〜ということで、味変程度にMiscを混ぜて以下の10問(Welcomeを除いて)を作りました。
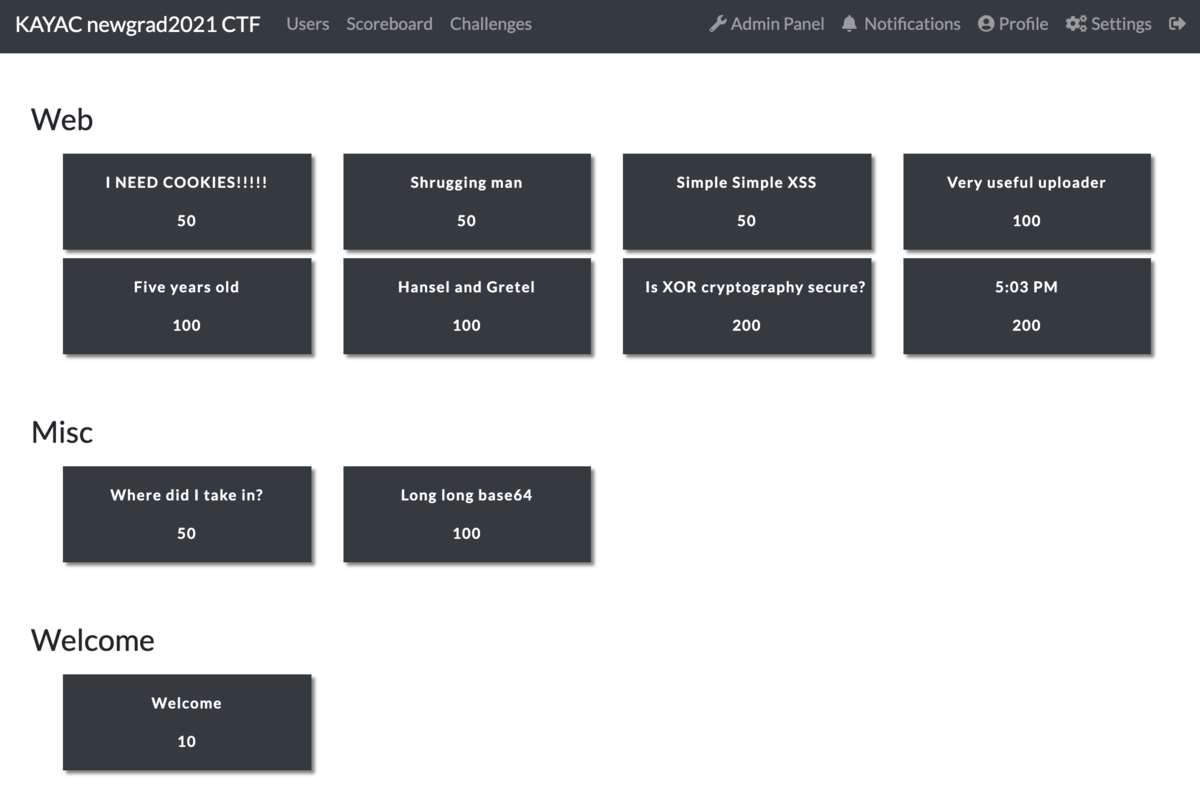
スコアサーバにはCTFdを使わせていただいています。本当はfbctfを使う予定だったのですがインストーラがaptにしか対応していなくて、うっかり「ディストリビューションは選べるならArchがいいです‼」と元気よく注文してしまったので変更しました。 CTFd最高。CTFdしか勝たん。いつもありがとうございます。
作問時に気をつけた点としては
- エスパー問を作らない(それはそう)
- 新卒研修の一環であることを意識する
- 基礎的な知識で解けるようにする
- ある程度まんべんなく要素を入れ込む
- 解いている間、解けたときの爽快感
- 問題同士が似ないようにする
あたりでしょうか。
特に、「新卒研修である」というところに重点を置いたので、CTFを知っている人向けに話すとだいたい「SECCON Beginners CTFの2ステップぐらい前」ぐらいの温度感だと思ってもらえばいいんじゃないかな、というぐらいの難易度で考えています。
大会時間は3時間目安ということでお話をいただいていたので、SECCON Beginners CTF ぐらいの難易度の大会でWebの100点問題がギリギリ解けるか解けないかぐらいの(よわい……)わたしが3時間掛けてギリギリ全完できるかな〜どうだろうな〜ぐらいの10問を揃えたつもりです。
具体的な作問のフローとしては、まず始めに最低限揃えるべきWeb周りの知識や攻撃手法をリスティングするところからはじめました。画像はその様子です。

実際はこのうち初歩的すぎるな〜という問題を抜いたりしてますが、まあ大まかにはこの通りに出しました。50点、100点の問題はここから作っています。
200点問題に関しては少し頭を捻ったり与えられた情報を大事にして複合的なアプローチで解く問題を増やしています。
全体的に簡単なものを多めに、配点の高い問題はそこまでの問題を解けていれば知識量的には十分解けるように、というのを意識しています。
テーマを決めたらまず架空のWrite-up(CTFの大会において、解いた問題を解説したブログ記事などをWrite-upと呼びます)を書いて想定解の流れを定め、そこからどんな見た目(メモアプリだったり、ファイルアップローダだったり)にするかね〜という肉付けをして実装、というのが大まかな流れでした。
作問記
例として2問ほど作問について詳しく触れておきます。
[Web] Very useful uploader (100)
この問題は上で紹介した作問ネタのうち
アップロードしたファイルを実行させちゃうぞ〜っ
ここから膨らませたネタです。そのまま〜!
以下が実装前にメモしてあった架空の Write-up です。
ページを開くとはじめから生意気な画像ファイルが数点と flag_encrypted.txt が用意されている。生意気な画像ファイルの中に「秘密鍵は環境変数に隠しておいた」とあるので、どうにかして環境変数を読み出すことを考える。アップローダは拡張子指定とかがされていないので試しに printenv する PHP ファイルとかを置いて踏んでみると秘密鍵が出てくるのであとはソイヤとして終わり
この問題はこの段階からいくらか変わっていて、ちょっと単純すぎるかな〜っというので多少捻りました。
具体的には、以下のようなコードを含む index.php のソースコードを配布しました(まあまあ長いので必要な部分以外は省略しています)。
include './get_user_dir.php'; $dir = get_user_dir(); include $dir . '/encrypt.php'; $flag = "XXXXXXXXXXXXXXXXXXXXXXXXXXXX"; $flag = my_encrypter($flag);
この my_encrypter という関数を[与えられた文字列をそのまま出力する]ように書き換えた encrypt.php を上書きアップロードしてください、という問題です。コードがヒントとして与えられる問題は他になかったので、そういう要素を入れられたのは良かったポイントですね。
この問題、テストプレイの時点で「 index.php を読んできてダンプするコードを書けばフラグが取ってこれてしまう」みたいな抜け穴がありまして、指摘していただいてから急遽カレントディレクトリに置いたダミーのPHPファイルをApacheのrewrite_modで上書きするように修正したのですが、如何せんApacheを扱うのがはじめてで見事にルーティングのバグを生み、終了間際まで実は解けない状態だった!という驚きの状況が発生しちゃったりしていました。
お詫びにアディショナル競技時間を20分追加しました。
そもそもrewriteなんてことができるのか〜っていうところからわたしは初耳だったので(インフラ周りの知識はギリギリNginxでリバースプロキシが作れる程度にしかもっていない貧相な知識量をしたわたしだ)勉強になる〜〜〜〜〜〜〜〜むずかし〜〜〜〜〜〜〜〜という感じでした。参加者のみなさん本当にすみません。情けな。
しかも修正後も encrypt.php をダンプすると暗号化部分が抜けちゃうという穴があったのでわあ……という感じです。任意コード実行系の問題を作るときはコードをダンプされないように気をつけましょう。情けな。
[Web] 5:03 PM (200)
この問題はタイトルから考えたものです。他にもいくつかタイトルから考えた問題があるのですが(Five years oldとかもそうです)、「200点作らなきゃいけないけど作問ネタ降ってこね〜〜〜〜〜〜〜〜!!!!期限だけが迫ってくるぜ!!!!!!!!!!!」と焦燥しながらApple Musicを眺めていたら同名の曲が目についたので「あ、ここから問題作れそうだな」と練ったらできた。
ちなみに作問のネタになった曲はわたしが一番好きなとあるアーティストの楽曲なのですが、作問のきっかけが好きなものだと自分のテンションも上がるし、タイトルに恥ずかしくない問題にしようと思えるのでとても良いです。この問題はかなり自分の中でもお気に入りの問題になりましたね。
解いてくれた人からの評判も結構良くてうれしかったです。
架空のWrite-upがこちら。
- 表示されたサーバログを見ると 6:00 PM 以降のものしかないが、ソースを見てみるとタイムスタンプをパラメータで取れそうな痕跡が残っているので 5:03 PM を含むように指定しリクエストを送り直す
- 5:03 PM のログを見ると WebShell からコマンド操作を行われた痕跡が残っているのでこれを利用することを考える
- とりあえずログの通りに何個か試してみると、 flag というファイルがあるっぽい
file flagとかするとELFファイルっぽいが、実行権限は与えられていなそう- 適当に権限がありそうなディレクトリを探してその中にコピーして
chmod +x flag→./flagするとフラグが取れるみたい
この問題はほとんどこのままですねー。違いは実行ファイルが隠しファイルになっていることぐらいか。
実際に出題したログがこんな感じです。
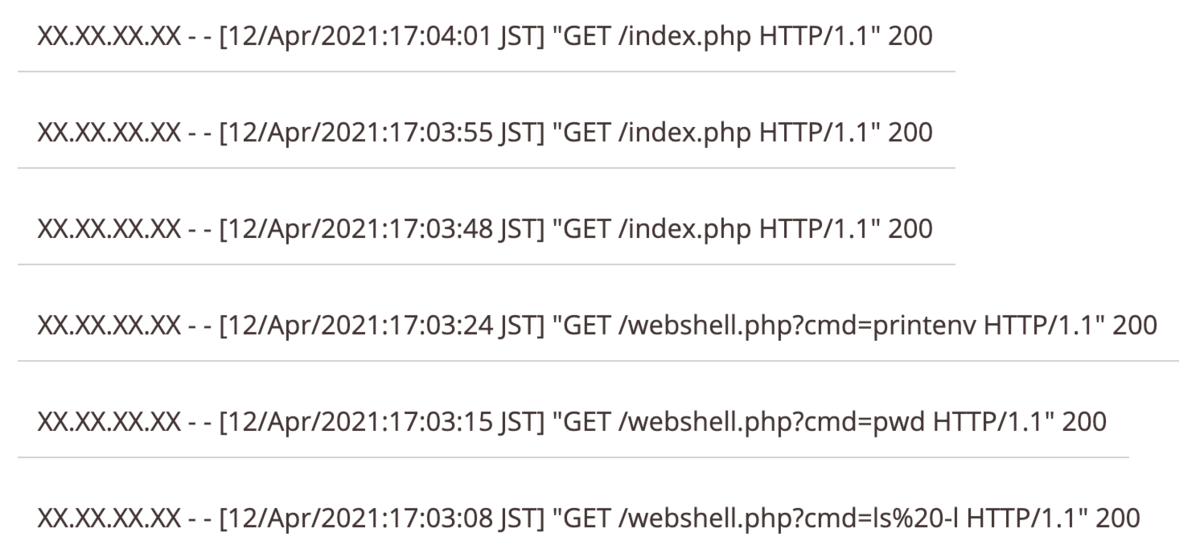
サーバログに残っている3つのコマンドの実行結果から
- 自分が書き込み・実行可能なディレクトリが存在する
- PATHに怪しげなディレクトリがある
という情報をしっかり汲み取れなければ問題が解けないので、今回の難易度感の中では良い感じにパズルゲーム感があったかなと思います。
実行ファイルはうっかり cat flag / strings flag とかでフラグを取られてしまうことがないようにフラグの文字列をバラした上で最適化なしのコンパイルを掛けて簡単に取られてしまうことを防ぎます。
また、Mac上でELFファイルを動かせる人であれば「wget とかしちゃお😃」みたいな発想になってしまうことがテストプレイ時にわかったのでこれもhostnameを参照して問題サーバのものでない場合エラーメッセージを吐くようにしています。
簡易的な対策だったので、できる人は実行ファイルを簡単に逆解析してhostnameを参照していることを特定しDockerコンテナ上で動かしたり分岐している部分のバイナリコードをNOPに書き換えてフラグを吐かせたり(Reversingっぽい、たのしい)できちゃったのでCTFのWeb問としてはあまり適切でないかな〜という感じもありましたが、正攻法でやったほうがどう考えても早くて簡単だということもあり、そこまでしたい人はご自由に、ぐらいのつもりで残したままにしました。
わたしは元々CTFはWebよりReversingの方が好きなひとだったので別解の話が弾んで非常にたのしかったです。
実はこの問題はわたしの知識不足で「WebShell上で操作をした際のカレントディレクトリにも実行ファイルをコピーできてしまい、特定の方法を使うと他の人がコピーした実行ファイルが見えてしまう」という穴があったので(大半の人は想定解通りに解いてくれましたが)、本来ならアクセスごとにコンテナを立てて隔離するだとかユーザ切り替え、chrootを活用する、みたいな上手な処理をすべきでしたね、という反省がありました。
今回は全体的にそういう穴の塞ぎ方みたいなところまで気が回らなかったり、そもそも割と孤独な作問期間だったのもあり(上手に質問をすれば上手に知見が返ってきていたのかもしれないが、作るのにいっぱいいっぱいで整理された質問文を考える余裕もなかった……)、もしも次にまた作問する機会があれば上手な構築をがんばりたいですね。
社内CTFを開催してみての感想
例年(2019年まで)は新卒研修の最終日に社内ISUCONを行うのが恒例だったようですが、たまたまちょっとだけ経験のあるわたしが新卒研修担当になって研修の題材として社内CTFという企画をさせていただいて、今まで社内でCTFに言及している人はほぼいなかったところを想像以上にたくさんのエンジニアの先輩に参加してもらい好意的な感想もいただけて非常に楽しく、わたしにとっても会社にとっても実りある試みになったかと思います!
来年からの新卒研修はまたどうなるのかわからないですが、「この年はこういうこともしたんだよね〜」という前向きな実績として残せた(よね?)ことを非常にうれしく思います。
当日は大会時間中スコアボードを眺めるのもすごくたのしかったです。これは試合終了後のスコアグラフですが、エンジニアのみなさんがMTGの合間を縫って熱戦を繰り広げる様子が見て取れます。たのしかったです
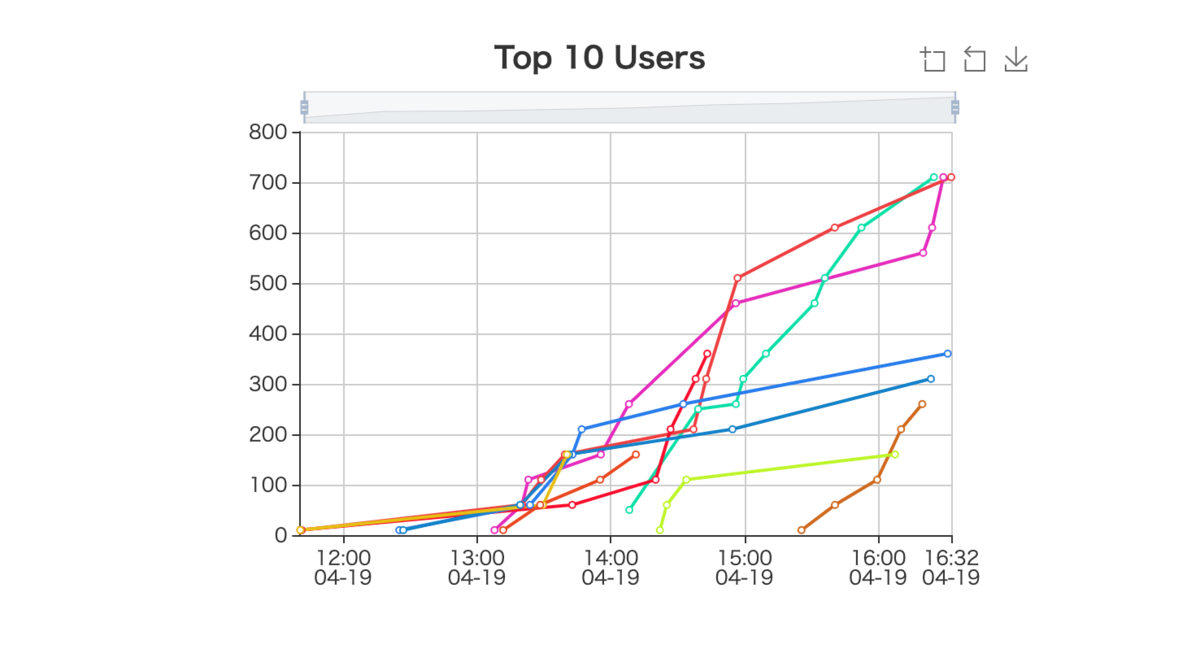
……という良い振り返りと同時に、もっと早くテストプレイを始められる状態にしておくべきでしたね、という反省が非常に強いです。
想定外の抜け穴を塞ぐためというのは当然そうなのですが、「これは問題として想定解に辿り着くまでの道筋が不親切すぎない?」とか「これがこの配点なのは簡単すぎるんじゃないかなあ」とか、フィードバックを受けてテコ入れをした問題がまるっきり歯応えの違う問題に生まれ変わったりするので。大会中にスコアボードを眺めながら意見聞いておいてよかった〜〜〜と本当に思いました。
その上、テコ入れをしていると「問題の終盤のアプローチが似通ってしまう(特に配点の高い問題)」みたいなことが起こり得るので(引き出しの少なさに問題がありますね)、そういう事態が起きても大丈夫なように問題修正用のマージンはしっかり取っておくべきですね〜という感じです。実装にどれだけ手数が掛かるかにもよりますが、作問:実装:修正=1:1:1ぐらいにバランス良く時間を割けるのが理想だと思います。
実際に300点問題としてひとつ大きいのを作っておくか〜と作問まで済ませていた Zip Slip Bad-trip という問題があったのですが(問題文の通りZip Slipという名前付きの脆弱性を利用した任意コード実行の問題になる予定でした)、上記でも紹介した Very useful uploader に作問修正・テコ入れを繰り返した結果解法アプローチが似てしまい、作問修正からするには時間が足りなかったという理由でお蔵入りになりました。問題名すごい気に入ってたのにな。声に出して読みたい問題名ですね。
あと新卒研修という意味では本当は実用性のあるテクニックなんかをもっと盛り込みたくて、Gitコマンドを駆使してあれこれする、みたいな問題もMisc枠で考えていた(具体的には、"環境変数をリポジトリにコミットしてしまったのでこいつを歴史から消し去りたいです‼"みたいな問題とか)のですが、実際業務コードでそんな巨大歴史改変されちゃ堪ったもんじゃないので不適切だろうなと思いお蔵入りになったりしています。
社内ではSlackが必須ツールなので、Slackのサーチ機能を駆使してわたしのtimesの奥深くからフラグになる文字列を拾ってきてください!みたいな問題も考えていましたがお蔵入りになったりしています。結構いろんな案がお蔵入りになりました。
よくあるCTFの大会ではMiscがそういう枠になりがちな気がしますが、CTF(というかJeopardy)という大会形式はセキュリティ文脈だけでなく開発小ネタクイズみたいなものにも使えるので新卒研修結構向いているんじゃないかなっていう気もしています。「新卒研修としてのCTF」はなかなか作問のしがいがありました。
余談ですが、走り出した初期は「custom emojiをflagとして置いて、reactionでsubmitするスコアサーバbotをつくったら楽しそう」みたいな話も出ていました。結局スコアボードとか問題一覧とかでフロントはいるし既存の使ったほうが良いねってことでお蔵入りになりましたが面白そうなアイデアではあったなあ。残念。
おわり
というわけで拙筆ではありましたが本年度の新卒研修について書かせていただきました。
わたしの作った問題を解いた後の研修プログラムとして新卒のみなさんにも問題を作ってもらい、みんなでわいわいと解くという大会も行いましたが、非常に歯応えのある問題が多くて解いていて楽しかったです!凝ったものが多くてうわ〜凝ってるな〜と思ったので、これについても機会があれば是非ブログに書いていただきたいところですね(昨年はアドベントカレンダーに新卒研修についてを書いている新卒エンジニア多かったけど今年はどうだろう)。
はじめての試みなのもありなかなか反省点も多かったですが、またどこかで活かせる機会が来たらいいねと思っています。
👇弊社に興味をお持ちの方はこちらもどうぞ👇
