SREチームの橋本です。SRE連載の3月号となります。
Amazon ECSのコスト最適化においてはFargate Spotが有効な手段となりますが、いつ中断されるか分からない性質上、その監視も併せて実施していく必要があります。今回はそのFargate Spotを本番環境で運用しているプロジェクトにおける取り組みを紹介します。
背景
Fargate (Amazon ECS on AWS Fargate) を用いると負荷に合わせた容易なスケーリングが可能になる一方、このときCPU使用率の安全マージンや予測のブレなどにより、リソースがやや過剰になってしまうこともあります。
Fargate Spotの代表的なユースケースと言えばユーザーに露出しない開発環境ではないかと思いますが、このような場合にコストを考えると、タスクの中断をある程度許容しての本番環境でのFargate Spot運用も可能な選択肢となってくるでしょう。
そこでリスク管理の手掛かりとして重要になってくるのが各種メトリクスであり、特にどのくらいSpotのタスクが動いているのか、中断率がどのくらいなのかを見つつ調整していく必要があります。 今回Fargate Spotを導入しSpotの比率を考える際にも、これらのメトリクスの情報が不可欠でした。
On-demand/Spotのタスク数の監視
使用状況メトリクスとしてアカウント全体でのSpot使用は確認できますが、負荷の掛かり方の違いもありECSサービスごとの使用量を見たいという状況でした。
私の参加しているプロジェクトで監視はMackerelを用いています。MackerelではAWSインテグレーションによりメトリックの自動取得ができますが、そもそもAWSにないメトリックでは仕方がありません。 ただ当該プロジェクトではmaprobeが稼働しており、任意のコマンドで取得したメトリックをMackerelに送信することができたため、今回もこれを利用しました。
例えば以下のようなシェルスクリプトにより、On-demandとSpotのタスク数を集計することができます。
#!/bin/sh # fargate_capacity # # ECSサービスごとのFargateキャパシティープロバイダーの利用状況を計測する。 # 出力例: # ecs.capacity.FARGATE.app 7 1699955130 # ecs.capacity.FARGATE_SPOT.app 1 1699955130 metric_prefix=ecs.capacity. timestamp=$(date +%s) cluster="" services="" while getopts c:s: OPT do case $OPT in c) cluster=$OPTARG ;; s) services=$OPTARG ;; esac done tasks=$(aws ecs list-tasks --cluster $cluster | jq -r '.taskArns[]') service_capacities=$(aws ecs describe-services --cluster $cluster --services $services | jq -r '.services[] | select(.capacityProviderStrategy) | .capacityProviderStrategy[].capacityProvider + "." + .serviceName') data="" for capacity in $service_capacities do data="$data\n$capacity 0" done service_pattern=$(echo $services | sed -e 's/ /|/g') task_capacities=$(aws ecs describe-tasks --cluster $cluster --tasks $tasks | jq -r ".tasks[] | select(.lastStatus == \"RUNNING\" and (.group | match(\"$service_pattern\"))) | ((.capacityProviderName // .launchType) + \".\" + (.group | split(\":\")[1]))") for capacity in $task_capacities do data="$data\n$capacity 1" done echo $data \ | awk '{ arr[$1] += $2 } END { for (i in arr) { if (i != "") { print i, arr[i] } } }' \ | awk "{ print \"$metric_prefix\" \$1 \"\t\" \$2 \"\t\" $timestamp }"
maprobeに対しては以下のように設定すると、各ECSクラスタ(Mackerel上ではECSロールが付いたホストとして扱われる)に対して、上記のスクリプトを起動しカスタムメトリックを投稿してくれます。
probes: - service: production role: ECS command: command: 'fargate_capacity -c {{ index .Host.Meta.Cloud.MetaData "cluster-name" }} -s "foo bar"'
Mackerelの実際の画面としては下図のようなグラフとなります。
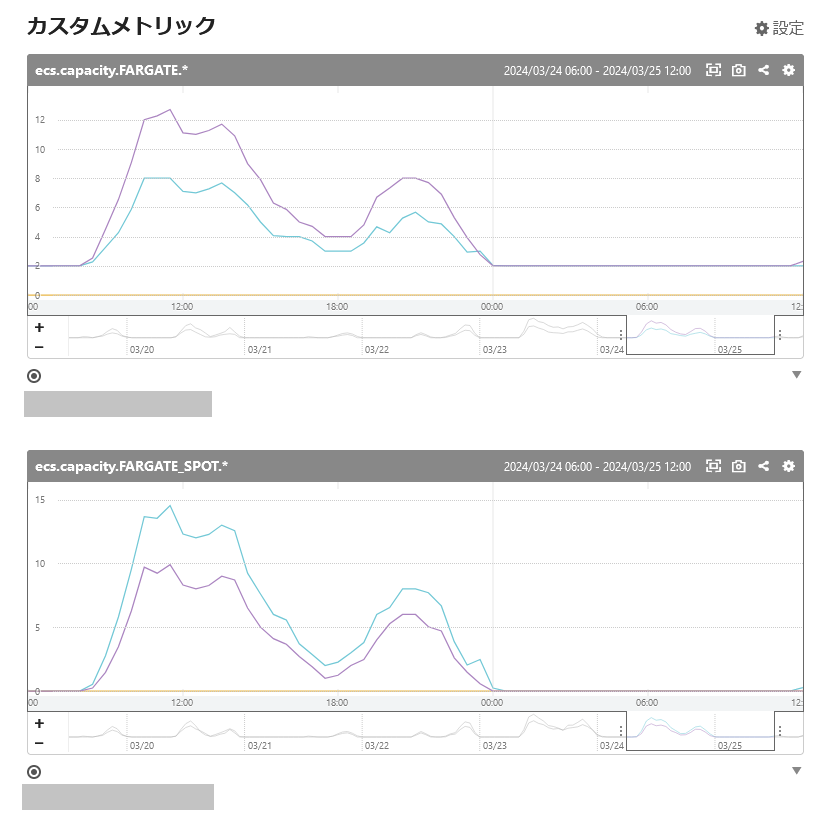
Fargate Spotの中断の監視
EC2スポットインスタンスであれば中断率が公表されていますが、Fargate Spotにはそのような情報がないようです。よって運用に当たっては自力で中断リスクを管理する必要があります。
またFargate Spotのタスク中断は公式情報によると、流れとしては通常のタスク停止と同様にSIGTERMが送られてstopTimeoutだけ待つ、となっているようです。しかし実際にはFargate Spotの中断だと正常終了しない……というケースも存在するでしょう。こうした時には中断時の挙動を調べる必要があります。
当該プロジェクトではECSタスクの異常終了イベントをCloudWatch Logsに保存しており、これについては例えばClassmethod様のAmazon ECS タスクの停止理由 (エラー内容) を CloudWatch Logs に保存する方法とその分析をしてみた | DevelopersIOをご覧頂ければと思いますが、EventBridgeからCloudWatch Logsへ直接渡して記録できるので簡単に実現できます。
Fargate Spotの中断はstoppedReasonがYour Spot Task was interrupted.となるため、Logs Insightsを用いると以下のようなクエリで抽出することができます。
fields time, detail.group
| filter detail.stoppedReason like 'Your Spot Task was interrupted'
| sort @timestamp desc
下図のようにグラフも表示され、簡単に分析することができます。
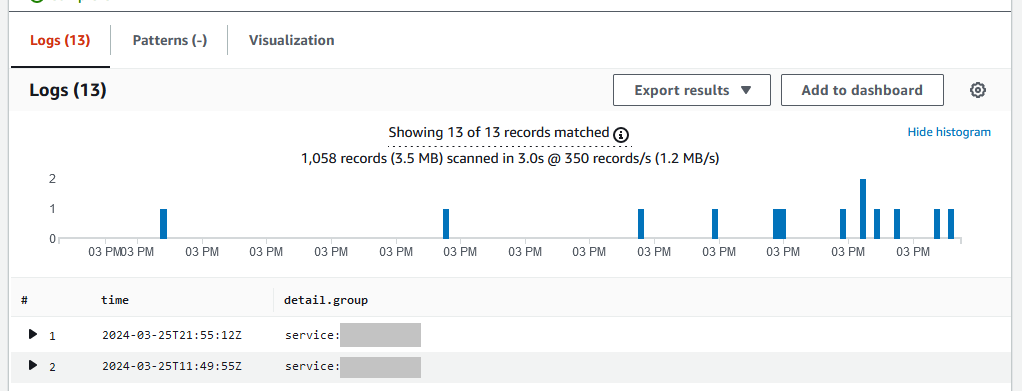
なおこうして中断率を見ると、概算で1時間あたり1%弱の中断率が計測されました。上記のEC2スポットインスタンスでは1ヶ月で5%未満といったデータが多いので、Fargate Spotではかなり性質が異なるのかもしれません。
またLogs Insightsの活用については、他にも「CloudWatch Logs Insights クエリを定期的に実行して結果をS3に置く」など紹介していますので併せてご覧ください。
まとめ
今回は自社OSSやAWSの各種サービスを活用したFargate Spotの監視について紹介しました。
Fargate Spotはその大きな割引率によってコスト最低化に当たり大きな魅力を持ち、また中断のリスクもコンテナアプリケーションとしてお行儀が良ければ、つまりステートレスであれば御しやすいものと言えます。 適切な監視と共にECSのキャパシティーの一部として活用すれば、スケーリングに更なる自由度をもたらすことができるのではないかと思います。