こちらはAWS Analytics Advent Calendar 2021の1日目のエントリーです。
こんにちは!今年からアナリティクスエンジニア(自称)を名乗ろうと思っている@mashiikeです。
Amazon Web Serviceには様々な分析向けのサービスがありますが、個人的に愛してやまないサービスとしてAmazon Redshiftというクラウドデータウェアサービスがあります。
この記事では、Redshiftの機能として連携方法が提供されていない他のAWSサービス、特にAmazon ComprehendやAmazon RekognitionなどのAIサービスにアクセスする方法についてお話します。
その方法を使うことで、SQL(もしくは、PartiQL)からAWSが提供する構築済みのモデルにアクセスできるようになり、少ない工数である程度のテキスト分析や画像分析が実現できます。
背景
今年のRedshiftアップデートの振り返り
今年のRedshiftには大きなアップデートがいくつかありました。 2021年4月にはJSONやNested Parquetなどの半構造化データをそのまま取り扱えるSUPER型がGAになりました。SUPER型はPartiQLの構文を使って直感的にクエリできるようになったためSQLとNoSQLのデータソースの統合がしやすくなりました。 2021年6月にAmazon Redshift MLがGAになり、SQLを用いてSage Maker Autopilotにアクセスできるようになりました。これによりSQL上で回帰や分類などの機械学習をとりあつかえるようになりました。
他にも階層データへのアクセスに便利なRecursive CTEや Redshift上からRDSやオンプレのMySQLへの透過的なアクセスを提供するFederated Query for MySQL compatibleなどもあります。 今年のre:Inventも期待できますね!
本題のまえふり
アップデートが重ねられてどんどん便利になっていくRedshiftですが、様々なAWSのサービスと連携可能です。
他にも先程紹介した、Redshift MLと呼ばれるAmazon SageMaker Autopilotと連携する機能は、Redshift上で機械学習の力を使うための手段の一つです。
ところが、SageMaker Autopilotを利用しても、自前で機械学習モデルを構築するのが大変な例があります。
それが、テキスト分析と画像分析です。
これらは、モデルを構築するための学習データを用意するのが大変です。そんなテキスト分析と画像分析ですが、AIサービスとしてAWSから構築済みのモデルが提供されています。
テキスト分析のためにはAmazon Comprehendを利用することで、すぐさまにキーフレーズや言語推定ができます。
画像分析のためにはAmazon Rekognitionを利用することで、コンテンツの節度分析やオブジェクト検出など一般的な分析ができます。
これらのAIサービスにRedshiftからアクセスできたら便利だと思いませんか?
例えば、my_tableのdescriptionカラムに自由入力のテキストデータが入っていたとします。
SELECT description, exf_detect_language(description) as lang_info FROM my_table
上記のようにSELECTするだけで、テキストデータが何の言語で書かれているかわかると便利なケースがあると思います。
SELECT description, exf_detect_key_phrases(description, 'ja') as key_phrases_info FROM my_table
また、上記のようにSELECTするだけで、テキストデータのキーフレーズを調べらたりすると便利なケースがあると思います。
特に、なにかのdescriptionの文字列や自由記述のアンケートデータが大量のある場合に、その中身をざっくり把握しようとしたとき、キーフレーズ分析して頻出単語を抽出できるととても便利だと思います。
他にも、画像データが保存されたS3へのURLが大量にRedshift上にあり、その情報を元にサービス運営上あまりよろしくない画像を抽出するケースでは、以下のようにできるととても便利だと思います。
CREATE TEMP TABLE image results as SELECT image_url, exf_detect_moderation_labels(image_url) as moderation_labels; SELECT * FROM ( SELECT r.image_url, l."Confidence" as confidence, l."Name" as label FROM results as r, r.moderation_labels."ModerationLabels" as l ) WHERE confidence > 0.95
このように、SQL一つでRekognition DetectModerationLabels APIにアクセスしてラベル情報をクエリできるとすごく便利だと思います。
今回はLambda UDFとSUPER型を用いて、その夢を実現します。
Lambda UDFを用いることで、AIサービスにアクセスする
Redshiftの外部の任意のサービスへアクセスする手段として、スカラー Lambda UDF の作成 があります。
Lambda UDFはSQLからユーザー定義関数(UDF)の一種で、指定したLambda関数をSQLから呼び出すことができます。
つまり、Lambda UDFのインタフェースを満たしたLambda関数が、RekognitionやComprehendなどにアクセスし、その結果をRedshiftへ返すことができれば夢の実現に一歩近づきます。
このLambda関数には様々な作り方があると思います。その例として、PoCコードをまとめたリポジトリを用意しておきました。また、aws-samplesから提供されているものも併記しておきます。
使いやすい形のLambda関数を用意しましょう。 さて、PoCコードでは以下のようなLambda UDFを定義しています。
CREATE OR REPLACE EXTERNAL FUNCTION exf_awscli(varchar(max)) RETURNS varchar(max) STABLE LAMBDA 'redshift-udf-awscli' IAM_ROLE 'arn:aws:iam::012345678910:role/warehouse';
上記のUDFは、Redshift上から任意のオプションでAWS CLIを実行するという、Super(特権的)な機能をもつLambda UDFです。
※もちろん、Lambda関数のIAM Roleに許されたものしか実際には実行できません。
このLambda UDFを使用して以下のようなSQLを実行すると
SELECT exf_awscli('aws comprehend detect-dominant-language --text "this is a pen."')
AWS CLIの結果のJSON文字列を取得できます。 上記の例のSQLはAWS CLIからAmazon Comprehend Detect the Dominant Language APIにアクセスして、指定の文字列の言語を推定してます。 結果として、以下のようなJSON文字列が得られます。
{ "Languages": [ { "LanguageCode": "en", "Score": 0.9984308481216431 } ] }
Lambda UDFから他のAWSサービスにアクセスして、結果を取得する方法はわかりました。
しかし、この方法の問題はAWS CLIの結果が VARCHAR(max)なJSON文字列でRedshiftに渡されるということです。
より具体的には、AWS CLIの結果として使われるJSONは当然のごとく配列構造やネスト構造を持つものが多いです。
このようなJSON文字列の各要素にアクセスする昔ながらの方法に、JSON_EXTRACT_PATH_TEXT関数とJSON_EXTRACT_ARRAY_ELEMENT_TEXT関数を使う方法があります。
この方法を用いた場合、先程の Detect the Dominant Language APIの例で、最も可能性が高い言語の結果にアクセスするとしたら以下のようになります。
CREATE TEMP TABLE result AS SELECT description , exf_awscli('aws comprehend detect-dominant-language --text '''|| description ||'''') as data FROM my_table; SELECT description, JSON_EXTRACT_PATH_TEXT(data, 'LanguageCode') as language_code, JSON_EXTRACT_PATH_TEXT(data, 'Score')::float as score, FROM( SELECT description, JSON_EXTRACT_ARRAY_ELEMENT_TEXT(languages, 0, true) as "language" FROM( SELECT description, JSON_EXTRACT_PATH_TEXT(data, 'Languages') as languages FROM result ) )
以上のようになるでしょう。 Redshift上からAWSサービスにアクセスできても、その結果を参照することが難しいと嬉しくありません。 一体どうすればよいのでしょうか?
JSONをSUPERに!
実は、背景で取り上げた2021年4月にGAとなった SUPER型がJSON文字列のRedshift上での取り扱いを解決してくれます。
SUPER型とは
解決方法の前に、SUPER型について軽く解説します。
例えば、以下のようなJSONL形式のデータが有ったとします。
{"country": "jp", "user": {"id": 1, "name": "hoge"}} {"country": "us", "user": {"id": 2, "name": "fuga", "lang": "en" }}
このデータをRedshift内部に取り込む場合は
CREATE TABLE access ( country VARCHAR(3), user SUPER );
と定義して、COPY構文で取り込むことができます。 この取り込んだデータは、
SELECT distinct "user"."id" FROM access
という形でデータにアクセスできるようになります。これがSUPER型の恩恵です。
実際の解決方法
問題を思い出すと、次の内容でした。
『Lambda UDFで AWS CLIの結果をVARCHAR(max)のJSON文字列として取得できたのは良いが、JSON文字列の取り扱いはとても大変だった!どうしたら良いのだろう。』
解決の方向性としては、VARCHAR(max)のJSON文字列をSUPER型に変換できれば良いわけです。
そんな都合の良い関数が実はあります!
JSON_PARSE関数です。
SELECT JSON_PARSE(exf_awscli('aws comprehend detect-dominant-language --text "this is a pen."'))
作成したLambda UDF exf_awscli関数を囲むと、最終的な出力はSUPER型になります。
JSON_PARSE関数で毎度囲むのも大変ですし、aws cliのコマンドを文字列結合して生成するのも大変です。
そこで、exf_awscli関数をSQL UDFで以下のようにラップします。
CREATE OR REPLACE FUNCTION exf_detect_language(VARCHAR(MAX)) RETURNS SUPER STABLE AS $$ SELECT JSON_PARSE(exf_awscli(('aws comprehend detect-dominant-language --text '''||$1||'''')::VARCHAR(MAX))) $$ LANGUAGE SQL;
実はLambda UDFでは戻り値にSUPER型を使用できませんが、通常のSQL UDFの場合はSUPER型が使えるのです。
以上で、特定の文字列を指定するとAmazon Comprehend Detect the Dominant Language API を実行し、その結果をSUPER型で取得できる exf_detect_language関数が出来上がりました。
実際の実行結果の例としては以下のような感じになります。
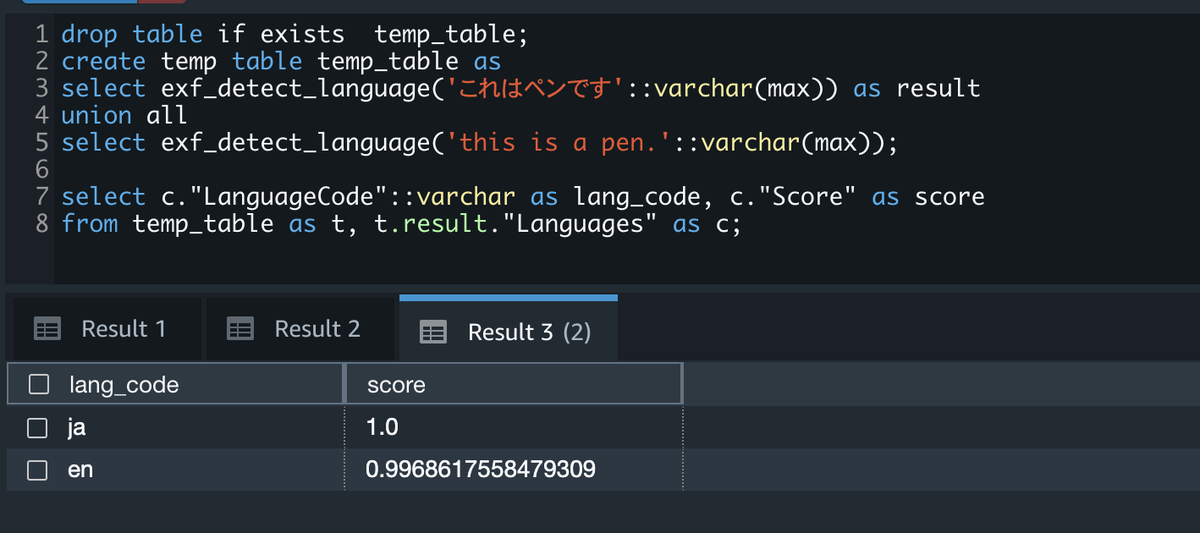
もちろん、exf_detect_key_phrases関数 も次のように定義できます。
CREATE OR REPLACE FUNCTION exf_detect_key_phrases(VARCHAR(MAX),VARCHAR(3)) RETURNS SUPER STABLE AS $$ SELECT JSON_PARSE(exf_awscli(('aws comprehend detect-key-phrases --text '''||$1||''' --language-code '''||$2||'''')::VARCHAR(MAX))) $$ LANGUAGE SQL;
Lambda関数の作り込み次第で、どのようなデータアクセスもできてしまうので用法と用量は守って適切に使いましょう!
おわりに
Redshift上から、Lambda UDFを使って他のAWSサービスにアクセスするということは昔からよく例がありました。 しかし、SUPER型の登場以前はそのLambda UDFの戻り値の取り扱いに苦労したことでしょう。 SUPER型の登場によって、Redshiftの至るところで半構造化データの取り扱い方が向上しています。 この記事では、その1例としてLambda UDFの戻り値をJSON文字列にし、JSON_PARSE関数を利用してSUPER型の戻り値を得るという内容でした。 この方法により、AIサービスへのアクセスが容易になり、よりRedshiftが便利になります。