この記事は Tech KAYAC Advent Calendar 2022 の10日目の記事です。
サーバサイドエンジニアのkolukuです。 今回は、ディレクトリ検索するようにS3 Selectを実行する社内向けツールをOSSとして作った話です。
過去のこの人のアドベントカレンダーはこちら(折りたたみ)
2021年 techblog.kayac.com
2020年 techblog.kayac.com
TL;DR
- ディレクトリ検索するようにS3 Selectを実行するOSSを書いた
brew install koluku/tap/s3s
- ALBやCFのログに対しても便利なオプションを用意したため新規プロジェクトでスタートダッシュしやすくなった
- OSS書くことで今までの学びを活かすことも、新たに得ることもできた
TOC
S3 Selectとは
S3 Selectはすでに知っているよという方は「koluku/s3sとは」まで飛ばして構いません
折りたたみ
S3バケットに配置したJSONやCSVといったファイルに対してSQLで直接クエリして抽出できる機能です。
この機能が便利な特徴として、
といった事が挙げられます。
例えば、S3バケットにログファイルが追加されたことをトリガーとして、エラーメッセージが含まれていないかをAWS Lambdaでクエリして通知するなどといったことができます。
例: 管理画面
検索対象のファイル情報からS3 Selectを選択して、入力ファイルの情報と結果をどのように出力するのかを設定します。
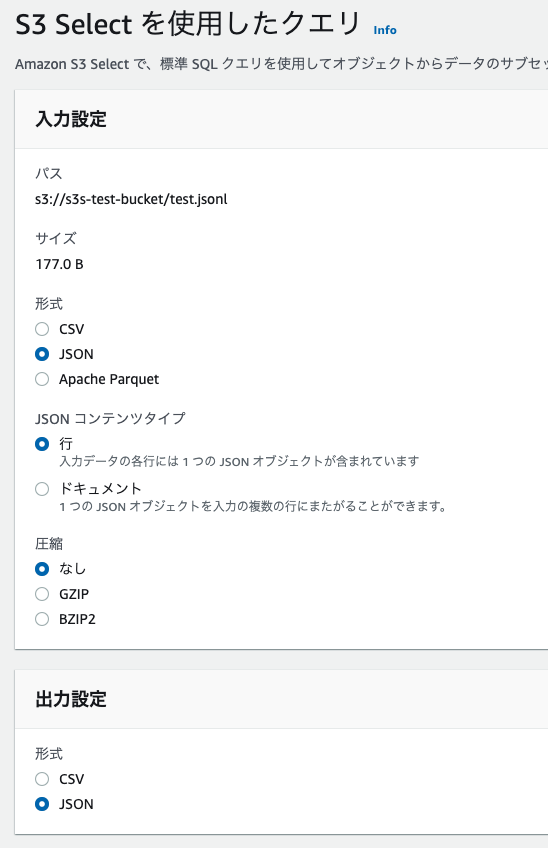
SQLはSELECTのみ使うことができ、WHEREやLIMITで対象を絞ることができます。
SELECT コマンド - Amazon Simple Storage Service
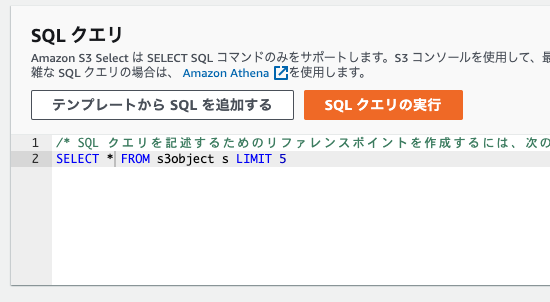
クエリ結果は直接表示され、ダウンロードから再利用可能です。
例: awsコマンド
管理画面で入力する内容をそのままコマンドラインに入力するためオプションの行が多くなります。
$ aws s3api select-object-content \
--bucket s3s-test-bucket \
--key test.jsonl \
--expression 'select * from s3object s LIMIT 5' \
--expression-type 'SQL' \
--input-serialization '{"JSON": {"Type": "LINES"}, "CompressionType": "NONE"}' \
--output-serialization '{"JSON": {}}' \
/dev/stdout
{"meta":"2022/12/01"} {"meta":"2022/12/02"} {"meta":"2022/12/03"} {"meta":"2022/12/04"} {"meta":"2022/12/05"}
koluku/s3sとは
ここからは自作したOSSツールの紹介です。まずは簡単な使い方です。
インストール
$ brew install koluku/tap/s3s
prefix以下でクエリの実行
$ s3s s3://bucket/prefix
{"time":1654848930,"type":"speak"}
{"time":1654848969,"type":"sleep"}
// $ s3s s3://bucket/prefix_A s3://bucket/prefix_B s3://bucket/prefix_C
思想
ツールを作るに至った前提として、S3 Selectの仕様として1ファイルずつしかクエリできないので、3つKeyをまとめてクエリしたい・特定のフォルダ(prefix)以下をまとめてクエリしたいということに対して不便です。
この点ですでに vast-engineering/s3select はprefix以下にあるKeyをすべて取得して1件ずつS3 Selectをするという手法をとっており、業務でもよくこちらを使っていました。
しかし、特定の日本語でエラーが起きる、ツール使うためだけにPythonを導入するのは取り回しにくいという点からkoluku/s3sという形で再開発することにしました。
強み: クエリが終わるまで本家より少し速い
191MBの検証用S3バケットにJSONを配置した物を用意してベンチマークを取ってみました。
$ aws s3 ls s3://s3s-test --recursive --human --sum Total Objects: 5431 Total Size: 191.1 MiB
hyperfineで vast-engineering/s3select と koluku/s3s で同じ条件で3回クエリしてベンチマークを取ったところ、約2.5倍早く実行が終わるという差が付きました。
$ hyperfine --runs 3 's3select s3://s3s-test/' 's3s s3://s3s-test/'
Benchmark 1: s3select s3://s3s-test/
Time (mean ± σ): 21.034 s ± 14.935 s [User: 14.132 s, System: 6.596 s]
Range (min … max): 12.392 s … 38.279 s 3 runs
Warning: The first benchmarking run for this command was significantly slower than the rest (38.279 s). This could be caused by (filesystem) caches that were not filled until after the first run. You should consider using the '--warmup' option to fill those caches before the actual benchmark. Alternatively, use the '--prepare' option to clear the caches before each timing run.
Benchmark 2: s3s s3://s3s-test/
Time (mean ± σ): 8.141 s ± 0.727 s [User: 8.872 s, System: 2.670 s]
Range (min … max): 7.428 s … 8.882 s 3 runs
Summary
's3s s3://s3s-test/' ran
2.58 ± 1.85 times faster than 's3select s3://s3s-test/'
どちらもAPIで結果をもらっているだけなので、ほぼGoでバイナリ化したものとPythonでの実行速度の差だと思います。
強み: ALBとCloudFrontのログに対してのクエリも便利
S3 SelectでS3バケットにあるCSVが読めるということは長年アプリケーション開発している方ならなんとなくピンときた方もいると思います。はい、ALB(Application Load Balancer)とCloudFrontのログも読むことができます。
ただし、ALBとCFのログをCSVとして読むのにちょっとネックな点として、S3 Selectでheaderが存在しないCSVで読み込んだ際に _2, _3 とカラム名がアンダースコア付きのインデックス番号を使ってアクセスすることになります。
そのままで取り扱うには辛いのでs3s側で文字列を置き換えて指定できます。
| index | ALB | CF |
|---|---|---|
| _1 | type | date |
| _2 | time | time |
| _3 | elb | x-edge-location |
| _4 | client:port | sc-bytes |
| ... | ... | ... |
以下README参照
$ s3s --alb-logs --where="s.`time` = '2022-09-01T00:00:00.000000Z'" s3://myapp-logs/alb/
また、ALBのログはある程度 / でprefixを切って階層構造にしてくれるのですが、CFのログは1階層にすべて置く仕様となっているので s3sの特定のprefix以下をすべて検索するという方針には向いていません。
そのため、--durationで現在時間までの期間や--since ~ --untilで期間を指定することで検索幅を絞ることができます。これはALBのログに対しても有効です。
$ s3s --cf-logs --since '2022-12-01 00:00:00' --until '2022-12-01 01:00:00' s3://myapp-logs/cf/
ただし、CloudFrontのログの場合は1つのバケットに対して1Distributionという前提で実装されているため、2つ以上置いていてもDistributionが名前昇順で早い1件しか検索されないのでお気をつけください。
強み: ディレクトリ移動するようにprefixを決めることができる
--delve オプションを付けるとprefixの位置からcd移動するかのようにprefixを移動できます。引数にprefixがない場合はバケット一覧から移動します。
$ s3s --delve
どのような挙動をするのかイマイチ伝わりづらいので動画のほうを見てもらえるばわかると思います。
クエリ後は標準エラー出力にどのprefixを元にクエリを実行したのか表示されます。パイプに流しても影響を受けないためそのまま $ s3s --delve | jq .のように使うこともできます。
OSSを作ってみてよかったこと
使われている様子を見て満足できる
嬉しくなってついついSlackでエゴサしてしまいます。

機能要望を聞いて俯瞰する
--delve オプションは元々実装予定ではありませんでした。というのも、僕がprefixを覚えて叩いていたり、整形されたパスで検索しづらさを感じていなかったため困らなかったのがあります。
ですが、社内からは新しいプロジェクトだとkey構造が安定していないし、覚えるのも面倒ということで意外と要望がありました。
例:

そうなると「この目的だけのツール」から「こういうことをするのに向いているツール」に進化せざるを得ないので、どういったツールなのかを見つめ直すのによく効きます。
アウトプットが増える
開発中に気がついたことや、機能を自分だけ知っててももったいないので社内Slackで便利情報を共有したり、ブログにまとめたりと。
- urfave/cli/v2ではRunContextでContextをもたせることができる - koluku's blog
- 不完全なjsonを断続的に[]byteで受け取る場合のデコード #go - koluku's blog
- errorgroup.SetLimitとTryGoでgoroutineの同時実行数を制御する
入社してすぐのわからないので助けて欲しいという状態から「S3の仕様について多少知っていますよ」「goroutineならある程度パターンを踏みました」と言えるようになります。
こういった積み重ねが自信や自己肯定感につながるんだろうなと感じました。
おわりに
OSSは作って終わりではありません、むしろメンテナンスを続けてこそが本番だと思います。
s3sの場合は「テストカバレッジ全然無いじゃん」「ライブラリとして使えるようにするにはこの構造はまずい」「ドキュメントを用意しないとわからないよな」「どう使われているのかインタビューしない」となど様々な課題があがっています。これらを解決していき、次のOSSの開発に活かせるようがんばりたいと考えてます。
この記事を読んでs3sを使いたいと思っていただけたのならインストールして感想いただけると幸いです。
それでは明日はhandlenameさんの「お願いを書く」です。お楽しみに!
Tech KAYAC Advent Calendar 2022
We are hiring!
面白法人カヤックでは一緒に働くサーバーサイドエンジニアを募集しています。