こんにちは。グループ情報部の 池田(@mashiike) です。
2019年から、面白法人カヤックと『北欧、暮らしの道具店』を運営する株式会社クラシコムとの協業プロジェクトとして、伴走型支援を行っており、その一環としてデータ基盤の開発・保守運用を行っております。
そして、3年前から「データ基盤安定化プロジェクト」として、クラシコム様のデータ基盤の大きな構造変化を継続して行ってきました。
この度、そのデータ基盤安定化プロジェクトが一旦の終了を迎え、その内容に関する記事がクラシコム様のNoteにて公開されました。
本記事では技術的な観点を中心に振り返ります。 プロジェクト全体の背景や進行の詳細については、ぜひクラシコム様のNote記事をご覧ください。
プロジェクトの背景と概要
3年前の当時、クラシコム様のデータ基盤は「ビジネスインテリジェンスツールであるLookerを、データ変換・加工・結合を行うデータパイプラインとして使用している」状態でした。
2025年現在、データ変換・加工・結合を行うデータパイプラインとしては dbt や Dataform などが有名です。しかし、私がクラシコム様のデータ基盤構築を始めた2020年頃は、これらのツールはまだ普及しておらず、軽量なSQLデータパイプラインを構築する手段としてLookerを選択しました。
この選択は、LookerのPersistent Derived Table(PDT)機能を活用してデータマートを構築し、AirflowやDigdagなどのワークフローエンジンを導入せずにデータパイプラインを構築できたため、当時の規模では最適でした。
しかし、2022年頃にはデータ基盤の規模が拡大し、いくつかの問題によってデータ基盤の不安定化とメンテナビリティの低下が進んでいました。
LookerのPDTによるデータパイプラインと当時の問題
LookerのPDTによるデータパイプラインの例は、以下のようなLookMLのコードです。
view: datamarts_first_model_updater {
derived_table: {
datagroup_trigger: source_data_updated
create_process: {
sql_step:
CREATE OR REPLACE TABLE `datamarts.first_model` AS
-- 初期構築のデータクエリ
SELECT ...
FROM `source_data`
;;
sql_step:
INSERT INTO `datamarts.first_model`
-- データ差分更新のためのクエリ
SELECT ...
FROM `source_data`
WHERE updated_at > (SELECT MAX(updated_at) FROM `datamarts.first_model`)
;;
sql_step:
CREATE OR REPLACE VIEW ${SQL_TABLE_NAME} AS
SELECT * FROM `datamarts.first_model`
;;
}
}
}
このように、derived_tableのパラメータである create_process を使うことで、データマートの差分更新を実現していました。
datagroup_triggerを使えば、データソースの更新を検知して自動的にデータマートを更新でき、とても便利でした。
また、datagroup_triggerに既存のデータマートを指定することで、first_model の更新が完了したら second_model、さらに third_model へと多段階でデータマートの更新を連鎖的に行うこともできました。
しかし、LookerのPDTをこの用途で利用する場合はいくつかの問題がありました。
1. 大規模化した際の依存関係の把握が困難
現在ではdbtやDataformなどのデータパイプラインツールが普及し、リネージグラフによる依存関係の可視化が容易です。
以下は、Firebaseのイベント処理に関するdbtのリネージグラフの例です。
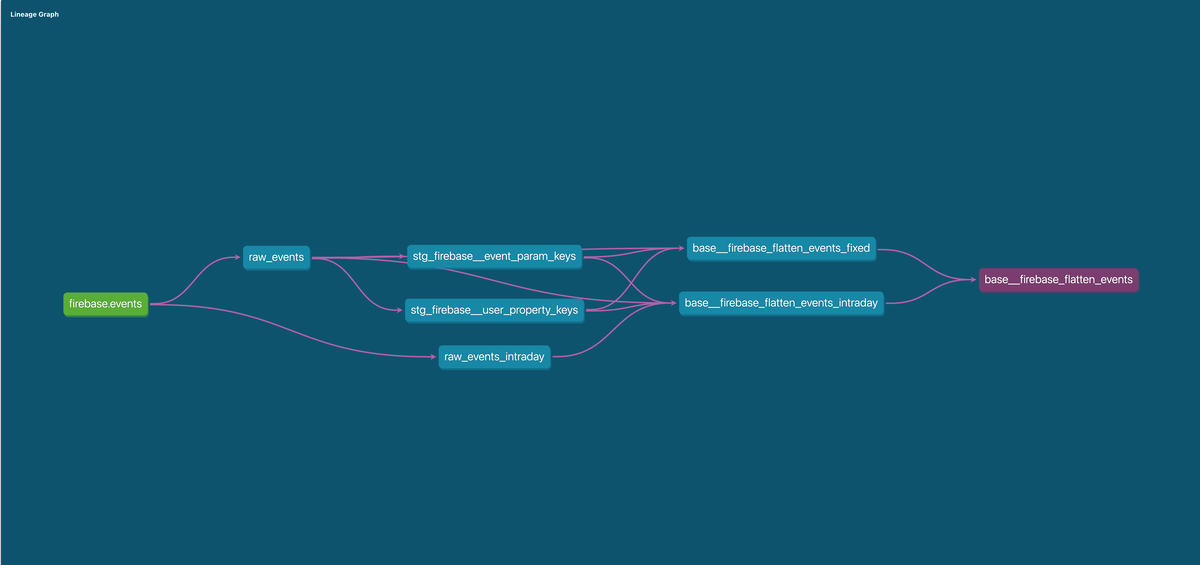
このように依存関係を簡単に理解できますが、LookerのPDTを使ったデータパイプラインではPDT間の依存関係を把握するにはLookMLを読むしかなく、非常に困難でした。
2. 複数の依存先を持つPDTの更新が安定しない
PDTの依存先が1つの場合は、その依存先が更新されると自動的にPDTも更新されます。しかし、複数の依存先を持つ場合、datagroupの仕組みでは「すべての依存先が更新されたときに1回だけ更新する」という設定ができませんでした。
そのため、複数の依存先がある場合はべき等性を保つようにし、それぞれの依存先が更新されるたびに毎回更新する運用をしていました。
この運用が不安定化の原因となっていました。例えばA,B,Cの3つの依存先がある場合、AとBが更新されたときはデータマートの更新が成功しても、Cが更新されたときにエラーが発生すると、AとBの最新データとCの古いデータを使った中途半端な状態が最終状態となってしまいます。
理想的には、A,B,Cすべての依存先が更新されたときに1回だけデータマートを更新する、というワークフローエンジンでは当たり前の挙動が求められます。
3. データテストがない
2025年現在、LookMLのデータテストは継続的インテグレーション(CI)の一環として存在しますが、これはDevelopment環境でのLookML変更が意図通りかを確認するためのものであり、データパイプラインのコンポーネントとして活用するのは難しいものでした。
データパイプライン上のコンポーネントとして、生成したテーブルやビューに対してテストを行い、それ以降の更新を停止したり異常通知を行うことは困難でした。そのため、データ基盤利用者がLooker上でデータを見て「何かおかしい」と気づくことが多発し、データ分析基盤への信頼性が低下していました。
TROCCOとdbtによるデータパイプラインの刷新
上記のような状況でしたので、データ基盤の安定化プロジェクトではデータ統合自動化サービス TROCCO と、そのTROCCOのdbt連携機能を用いてデータパイプラインの刷新を行いました。
具体的には、PDTで更新していたデータマートをdbtのモデルに置き換え、TROCCOのデータ転送後にdbtジョブを実行することで、データ搬送と更新を一気通貫したデータパイプラインを目指しました。
例えば、先ほどのLookerのPDTの例をdbtで書き直すと以下のようになります。
{{ config(
materialized='incremental',
...
) }}
SELECT ...
FROM {{ source(...) }}
{{ if is_incremental() }}
WHERE updated_at > timestamp(_dbt_max_partition)
{{ endif }}
このようにシンプルで把握しやすくなります。また、モデル間の依存関係や実行制御もdbtが自動的に解決してくれるため、依存関係の把握や更新の安定性も向上しました。
さらに、dbtにはデータテスト機能もあり、テストを通過しない場合はデータマートの更新を停止できるため、データ基盤の信頼性も高まりました。
また、TROCCOの通知機能を活用することで、例えばデータテストを通過せずdbtジョブが失敗した場合にSlackへ通知することも可能になりました。
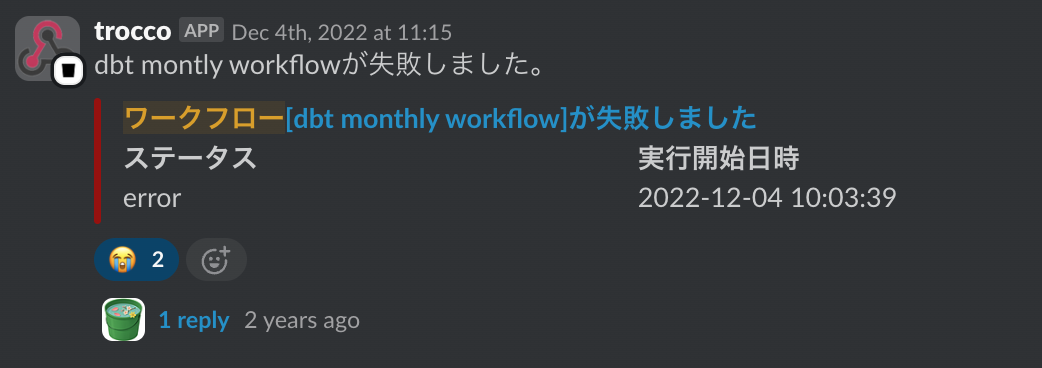
この通知機能により、「今、Lookerのデータを見ても正しいデータが出ない」とデータ基盤利用者にも可視化されるようになり、データ基盤の信頼性と安定性向上に寄与していると思っています。 加えて、TROCCOがdbtを実行するため、インフラ管理が不要だった点も大きなメリットでした。
プロジェクトの進行に際して、苦労した点
このプロジェクトを進める中で、最も苦労した点はデータマートの再設計です。
LookerのPDTを使用したデータパイプラインを移植する場合、多くのケースでは書いてあるSQLをそのままdbtのモデルに移植することができました。これらは元のデータマート設計が適切で、再設計を必要としないものでした。
しかし、データ基盤の進化に伴いパフォーマンスが劣化したものや、複雑になっているもの、追加の要望があるものなどは再設計が必要でした。これらは再設計を行ったうえでdbtのモデルに移植し、その移植したモデルによって生成されるデータマートに切り替える作業が必要でした。
この記事では、苦労した例を2つ紹介します。
GA4/Firebaseのイベントをニアリアルタイム(intraday)のものも含めて閲覧したいので再設計
データ基盤の利用拡大に伴い、データの鮮度に対する要求が上がったものがありました。それは、GA4/Firebaseというアクセス解析ツールからのイベントデータを用いた分析に関するものです。
このデータは、2種類の状態があります。
- すべてのデータが出揃った状態のもの(events_YYYYMMDD)
- ニアリアルタイムで更新されている状態のもの(events_intraday_YYYYMMDD)
当時は、LookerのPDT上ではそれほど複雑なデータ変換を実装できなかったため、データの更新は良くて1日1回という状態で events_YYYYMMDD のデータをもとに更新していました。この「良くて1日1回」というのは、GA4/Firebaseのデータ更新頻度によるものです。
データの処理には 24~48 時間かかることがあります。その間、レポートのデータに変化が生じる場合があります。 データのサイクルとして、events_intraday_YYYYMMDDはデータ処理が完了したら同日のevents_YYYYMMDDに置き換わります。
ところが、近年では『北欧、暮らしの道具店』 の成長に伴いデータ量が増えたため、データの処理時間が24時間を超えるケースが頻発してきました。既存の状態では events_YYYYMMDD のデータ到着が遅れた場合、閲覧できるデータが古い状態のままとなり、データ基盤利用者にとっては不便な状態でした。
この課題を解決したいと考えましたが、当時の基盤では複雑な更新方法を実装するのが難しく、ニアリアルタイムで更新されている状態のもの(events_intraday_YYYYMMDD)も含めてデータマートを作ることができない、という壁がありました。
dbtの導入によって複雑な更新方法が可能になり、ニアリアルタイムで更新されているデータも含めてデータマートを作れるように再設計できました。
このデータマートの再設計には、dbtの開発元であるdbt Labsが実験的に実装しているLambda viewsというパターンを用いました。Lambda viewsは events_YYYYMMDDを処理するモデル(差分更新テーブル)と、events_intraday_YYYYMMDD(DB View)を処理するモデルを組み合わせます。
最終的にデータ基盤利用者に提供するデータマートでは、以下のようにその2つを結合したViewを作成して提供します。
{{ config(
materialized='view',
) }}
SELECT * FROM {{ ref(`events_intraday`) }}
UNION ALL
SELECT * FROM {{ ref(`events_fixed`) }}
このようなデータマートは、依存関係を自動的に解決してくれるdbtの導入によって、簡単に実現できるようになりました。依存先が複数あるデータマートの更新が安定しなかったプロジェクト開始当時の基盤では、達成できなかった要件の一つです。
ExploreがLiquidで複雑化していたための再設計
Lookerには、Liquidという機能があります。この機能を利用することで、データ基盤利用者が選択したUI上のディメンジョンやメジャーによって、SQLのクエリを動的に変更することができます。
一例として、以下のようなLookMLのコードがあります。
view: customer_facts {
paramter: timeframe {
type: unquoted
allowed_value: {
label: "日次"
value: "daily"
}
allowed_value: {
label: "月次"
value: "monthly"
}
allowed_value: {
label: "年次"
value: "yearly"
}
default_value: "daily"
}
derived_table: {
sql:
with
base as (
SELECT
{% if timeframe._parameter_value == "daily" %}
DATE_TRUNC(order_date, DAY) AS ymd,
{% elsif timeframe._parameter_value == "monthly" %}
DATE_TRUNC(order_date, MONTH) AS ymd,
{% else %}
DATE_TRUNC(order_date, YEAR) AS ymd,
{% endif %}
SUM(sale_price) AS total_sales_price
FROM
order
)
SELECT
t.ymd,
t.total_sales_price,
SAFE_DIVIDE(t.total_sales_price, p.total_sales_price) AS year_over_year
FROM base as t
JOIN base as p
ON t.ymd = DATE_ADD(p.ymd, INTERVAL 1 YEAR)
;;
}
}
これは、売上などのKPIを日次、月次、年次で集計し、その時間粒度でもってYoY(前年同月比)を計算するという想定のものです。今では、アップデートによって新しいメジャー period_over_period が追加されたのでそちらで解決できますが、当時はこのような形でLiquidを使用してYoYをデータ基盤利用者に提供しているケースもありました。
この例ではパラメータの数は1つなのでそれほど複雑ではありませんが、データ基盤の成長に伴いパラメータの数が7種類や8種類と多いものも存在しており、一部のExploreで非常に複雑になっている状態でした。
今回のプロジェクトに際して、可能であればこのような複雑なExploreも簡便化したいという要望もあり、再設計を行いました。
この再設計については、コンサルティングでご一緒している風音屋のゆずたそさんにも相談に乗っていただき、議論を重ねながら整理を進めました。
現時点でも明確な答えが出ていませんが、dbtに移行することにより様々なアプローチの選択肢ができたのは良い点です。
例えば、パラメータの全パターンをテーブルとして先に計算するという方針もあります。
{{ config(
materialized='table',
) }}
with
{%- for timeframe in ['daily', 'monthly', 'yearly'] -%}
base_{{ timeframe }} as (
SELECT
{% if timeframe == "daily" %}
DATE_TRUNC(order_date, DAY) AS ymd,
{% elif timeframe == "monthly" %}
DATE_TRUNC(order_date, MONTH) AS ymd,
{% else %}
DATE_TRUNC(order_date, YEAR) AS ymd,
{% endif %}
SUM(sale_price) AS total_sales_price
FROM {{ ref('order') }}
GROUP BY 1
),
metrics_{{ timeframe }} as (
SELECT
'{{ timeframe }}' AS timeframe,
t.ymd,
t.total_sales_price,
SAFE_DIVIDE(t.total_sales_price, p.total_sales_price) AS year_over_year
FROM base_{{ timeframe }} as t
JOIN base_{{ timeframe }} as p
ON t.ymd = DATE_ADD(p.ymd, INTERVAL 1 YEAR)
){% if not loop.last %},{% endif %}
{% endfor -%}
SELECT * FROM metrics_daily
UNION ALL
SELECT * FROM metrics_monthly
UNION ALL
SELECT * FROM metrics_yearly
このように、パラメータの全パターンをテーブルとして先に計算しておき、Exploreではそのテーブルを参照するだけにする方法です。ただし、パターンが多すぎるとBigQueryから HTTP Status 413: Request Entity Too Large というエラーが出てしまうこともあり、現時点ではこの方針は避けています。
2025年5月現在では、dbtのCustom Materializationを用いて、dbt上でBigQueryのテーブル関数として実装する方法が良いのではないか?という状態になっています。
{{ config(
materialized='table_function',
argument=[
'timeframe STRING',
]
) }}
WITH base AS(
SELECT
case timeframe
when 'daily' then DATE_TRUNC(order_date, DAY)
when 'monthly' then DATE_TRUNC(order_date, MONTH)
else DATE_TRUNC(order_date, YEAR)
end as ymd,
SUM(sale_price) AS total_sales_price
FROM {{ ref('order') }}
GROUP BY 1
),
SELECT
t.ymd,
t.total_sales_price,
SAFE_DIVIDE(t.total_sales_price, p.total_sales_price) AS year_over_year
FROM base as t
JOIN base as p
ON t.ymd = DATE_ADD(p.ymd, INTERVAL 1 YEAR)
WHERE t.timeframe = @timeframe
この辺は、データパイプラインの移植とは別の話ではあるので、徐々に簡便化したいと思っています。 以前よりもメンテナビリティが上がったことが良いと捉えています。
まとめ
クラシコム様のデータ基盤開発当時は最適だったLookerのPDTを使ったデータパイプラインも、時代の変化とデータ基盤の成長に伴い、さまざまな課題が発生しました。
これらの課題を解決するため、TROCCOとdbtを用いてデータパイプラインを刷新し、データ基盤の安定化を図りました。このプロジェクトは3年かけて進行し、先日すべてのLookerのPDTを使ったデータパイプラインの移植が完了しました。
現在はデータマート作成のデータパイプラインはすべてdbtで管理され、今の時代に即したものに刷新されています。このプロジェクトを通じて、データ基盤の安定化と信頼性向上を実現できたことを嬉しく思います。
今後も、クラシコム様のデータ基盤のさらなる発展と、データを活用したビジネスの成長を支援していきたいと思います。