面白法人グループ Advent Calendar 2025 の18日目の記事になります。
こんにちは!カヤック技術部の大脇です。
本記事では、複数のAIエージェントが会話履歴を共有するときに発生する「コンテキスト汚染」と、Mastra の Agent Networks を使った解決方法をご紹介します。
はじめに
LLMと対話するとき、会話の流れを維持するために直近の会話履歴をコンテキストに含める手法がよく使われます。 これを複数のエージェントに適用しようとしたとき、単純に会話履歴を共有するだけでは出力が安定しないという問題に直面しました。
例えば丁寧な標準語で会話するエージェントと、おすすめのランチを関西弁で紹介するエージェントがいたとします。 おすすめのランチを聞くと関西弁のエージェントが紹介してくれて、 標準語のエージェントが最後にフォローアップしてくれるという流れを期待しています。
👤 ユーザー: こんにちは! 🤖 標準語: こんにちは、何かお手伝いできることはありますか? 👤 ユーザー: おすすめのランチ教えて! 🤖 関西弁: ランチやったら○○がめっちゃおすすめやで!ボリューム満点でコスパ最高やねん! 👤 ユーザー: ありがとう! 🤖 標準語: お役に立ててよかったです。○○はボリューム満点でめっちゃええらしいですわ! ← !?!?
丁寧な標準語で話すはずのエージェントが、関西弁で話しはじめました。
このように、あるエージェントの発言が、別のエージェントの振る舞いに影響を与えてしまう場合があるのです。
私が開発で使用しているTypeScript製のAIエージェントフレームワーク「Mastra」では、「Agent Networks」という機能がこのような課題の解決の役に立ちました。
今回は「Agent Networks」がどのようにエージェント同士の会話を共有して、コンテキストの汚染を防ぎながら会話を成立させているのかご紹介します。
Agent Networks とは
Agent Networks は、複数のエージェントやツールを束ねて、複雑なタスクを自動で振り分ける仕組みです。
中心となる「ルーティングエージェント」が、ユーザーのリクエスト内容をLLM で解釈し、どのエージェント・ワークフロー・ツールを使うべきかを判断するのが特徴です。
ではなぜこの機能が会話内のコンテキスト汚染を防ぐことができているのでしょうか。
1. エージェントは「ツール」として呼び出される
Agent Networks では、ルーティングエージェントが扱うエージェント(以後サブエージェント)はこのように定義します。
export const orchestrator = new Agent({ name: "Orchestrator", instructions: `適切なエージェントを選んでください`, agents: { kansaiAgent, standardAgent }, // ← エージェント定義 model: "google/gemini-2.5-flash" });
agents に渡されたエージェントは、内部で agent-${エージェント名} という名前のツールに変換されます。
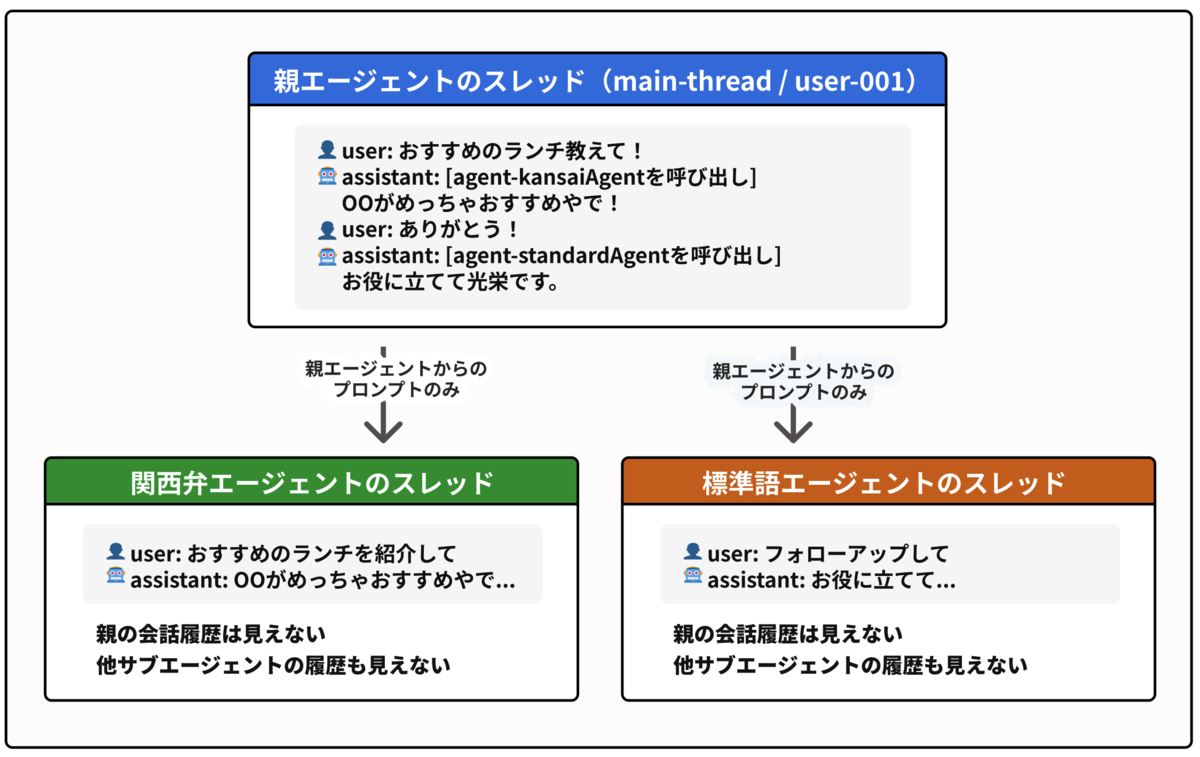
親エージェントのスレッドを見ると、サブエージェントの応答はツール呼び出しの結果として記録されていることがわかります。
以下は親エージェントのスレッドに保存されるメッセージの例です。
// ユーザーメッセージ { "role": "user", "content": "おすすめのランチ教えて" } // オーケストレーターの応答(tool_call) { "role": "assistant", "content": [ { "type": "tool-call", "toolCallId": "call_abc123", "toolName": "agent-kansaiDialectJapaneseAgent", "args": { "prompt": "おすすめのランチを紹介して" } } ] } // ツール結果(tool_result) { "role": "tool", "content": [ { "type": "tool-result", "toolCallId": "call_abc123", "toolName": "agent-kansaiDialectJapaneseAgent", "result": { "text": "ランチやったら○○がめっちゃおすすめやで!ボリューム満点でコスパ最高やねん!", "subAgentThreadId": "e55b7cf9-f1da-4d5f-9a86-cf8117bf8806", "subAgentResourceId": "Orchestrator Agent-agent-kansaiDialectJapaneseAgent" } } ] }
サブエージェントがツールとして扱われることで、親エージェントと同じスレッド上で直接動作することがなくなります。呼び出しは必ずツール経由となり、コンテキストの混入を構造的に防ぎます。
2. 呼び出しごとに独立したスレッドが自動生成される
サブエージェントが呼び出されるたびに、Mastra は新しい threadId と resourceId を自動生成します。
{ "toolName": "agent-kansaiAgent", "args": { "prompt": "おすすめのランチを紹介して" }, "result": { "text": "ランチやったら○○がめっちゃおすすめやで!ボリューム満点でコスパ最高やねん!", "subAgentThreadId": "e55b7cf9-f1da-4d5f-9a86-cf8117bf8806", "subAgentResourceId": "orchestrator-agent-kansaiAgent" } }
DBを確認すると、各サブエージェントは完全に独立したスレッドを持っています。
| threadId | resourceId |
|---|---|
| e55b7cf9-... | orchestrator-agent-kansaiAgent |
| d30d62b6-... | orchestrator-agent-standardAgent |
開発者が resourceId や threadId を手動で管理する必要はなく、Mastra が自動でスレッドを分離し、不正な組み合わせはエラーで拒否してくれます。
3. 渡されるのはプロンプトのみ
親エージェントからサブエージェントに渡されるのは、親が生成した指示文(プロンプト)だけです。会話履歴全体は渡されません。
DBを確認すると、サブエージェントのスレッドには親から渡されたプロンプトとその応答だけが保存されています。
親エージェントのスレッド(ツール呼び出し部分)
{ "toolName": "agent-kansaiAgent", "args": { "prompt": "おすすめのランチを紹介して" } }
サブエージェントのスレッド
| threadId | role | content |
|---|---|---|
| e55b7cf9-... | user | おすすめのランチを紹介して |
| e55b7cf9-... | assistant | ランチやったら○○がめっちゃおすすめやで!... |
ユーザーの元の発言は「おすすめのランチ教えて!」でしたが、サブエージェントに渡されているのは親エージェントが解釈・変換した「おすすめのランチを紹介して」です。親エージェントは単なるプロキシではなく、サブエージェントに何をどう伝えるかをコントロールしています。
親スレッドの会話履歴(「こんにちは!」など)や、他のサブエージェントの発言は一切含まれていません。
つまり、親エージェントがユーザーの全会話履歴を見て「おすすめのランチ教えて」という要望を解釈し、サブエージェントには「おすすめのランチを紹介して」という1つの指示だけを渡しています。サブエージェントからは他のエージェントの発言履歴も、ユーザーとの過去の会話も見えません。
親エージェントのスレッドには全会話履歴が残りますが、サブエージェントにはプロンプトだけが渡され、それぞれ独立したスレッドで動作します。 会話履歴全体を渡すと、どこで汚染が起きるか予測困難ですが、この設計なら親エージェントが何を伝えるかを明示的にコントロールできます。
実験結果
実際に Agent Networks を使った場合と使わなかった場合でワークフローを組んで比較しました。
期待通りの結果が得られたことが確認できました。
| 呼び出し方法 | 標準語エージェントの応答 | 結果 |
|---|---|---|
| 直接呼び出し | 「お役に立てて光栄やで!また聞いてな!」 | ⚠️ 汚染発生 |
| Agent Networks | 「お役に立てて光栄です。ぜひお楽しみください。」 | ✅ 汚染なし |
まとめ
Agent Networks がコンテキスト汚染を防げる理由として以下の3つの仕組みをご紹介しました。
- サブエージェントを「ツール」として登録し、構造的に分離
- サブエージェントごとに独立したスレッドを自動生成
- 親からサブへはプロンプトのみを渡し、会話履歴は渡さない
このエージェントの専門性を限定し、必要な情報だけをコンテキストに入れるという設計原則は、Anthropic の Sub-Agents や Skills にも現れていると考えられます。
本件により、専門を分担することでタスク処理の精度向上につながるということが、実務を通じて理解を深めることができました。
明日は id:ikeda-masashi さんの記事になります。