はじめに
この記事は【カヤック】面白法人グループ Advent Calendar 2024の5日目の記事です。
こんにちは。中山と申します。
TextMesh Proでテキストを円形に配置できるようにする方法について紹介します。
こういうやつです。

実装はGitHub - quartorz/FlexibleTextMeshに置いてあります。
なお、アラビア文字やデーヴァナーガリーのように前後が繋がる文字がある場合はこの方法ではうまくいきません。
計算について
どのような計算をするか
モンゴル文字のように当てはまらないものもありますが、多くの文字は横方向に配置されます。なので、横長の四角形の領域に配置された文字をドーナツ型の領域に並べ直すことを考えます。
そして、そのような変換をどのような単位で行うかについては、
- メッシュの形は気にせず、頂点単位で行う
- メッシュの形が保たれるように、メッシュ単位で行う
の2つに加えて、Unicodeでは複数のコードポイントで1文字を表すことがあるので、
- 書記素単位で行う
ということも考えることにします。
具体的な計算方法
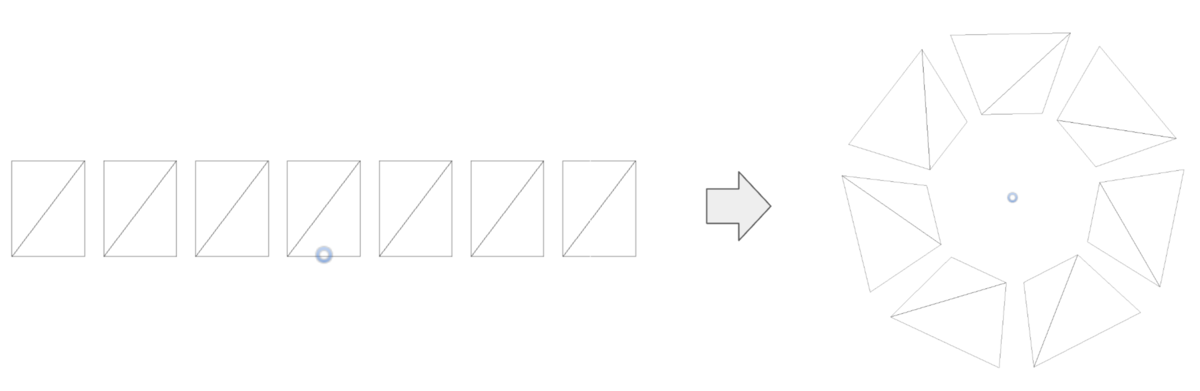
ここでは、以下の画像のように長方形の両端をくっつけてドーナツ型にするような変換を考えることにします。こうすることでテキストが1行しかない場合に繋ぎ目が目立たない変換ができるからです。

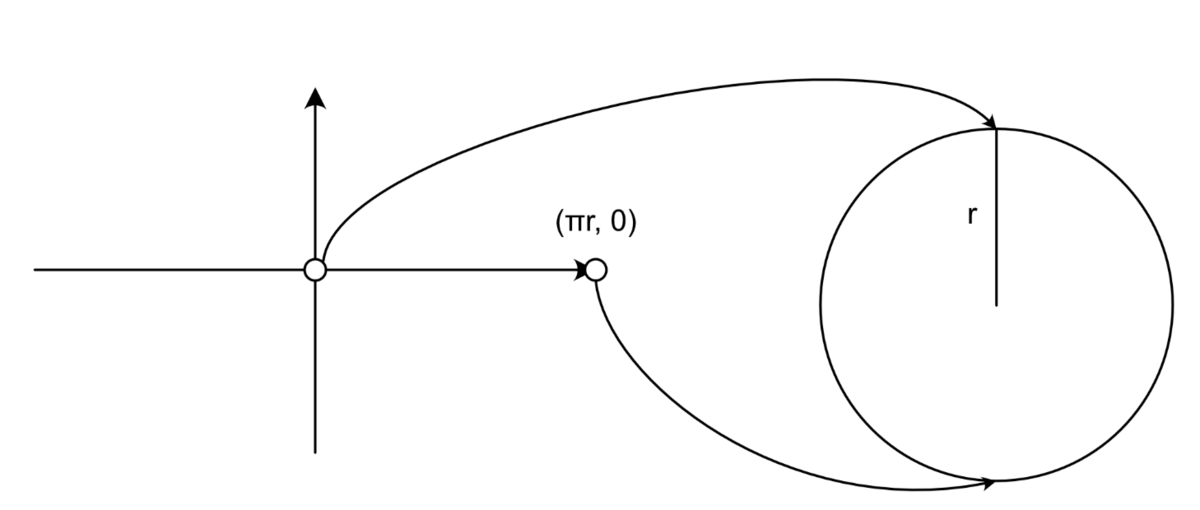
そして、x軸がスケールを変えずに円に変換されるような変形を考え、が半径
の円の真上、
が円の真下に来るように変換することを考えます。
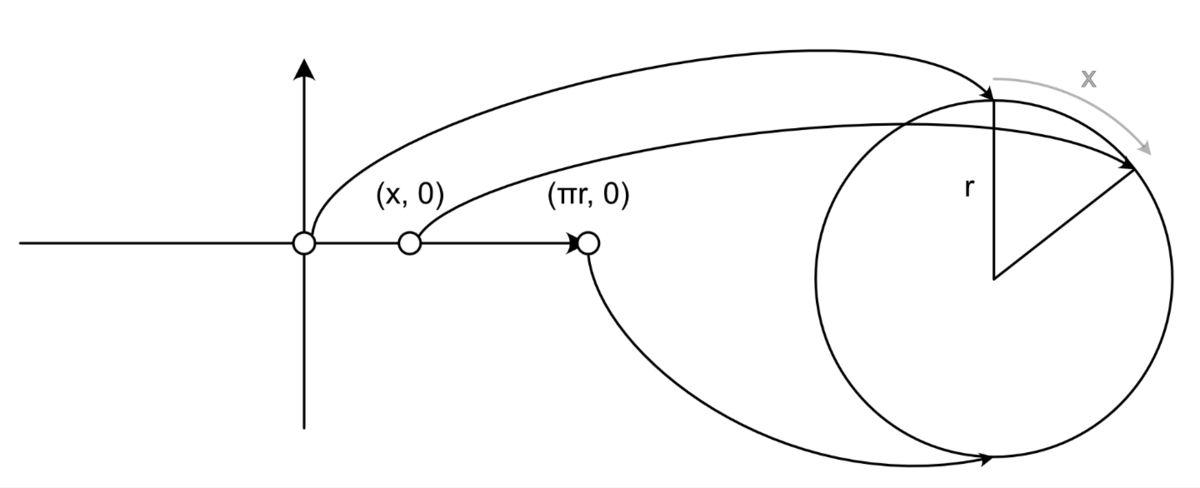
そうすると、は円の真上から
ラジアンだけ回転した座標に変換されるので、
や
を使って変換先の座標が計算できることがわかります。
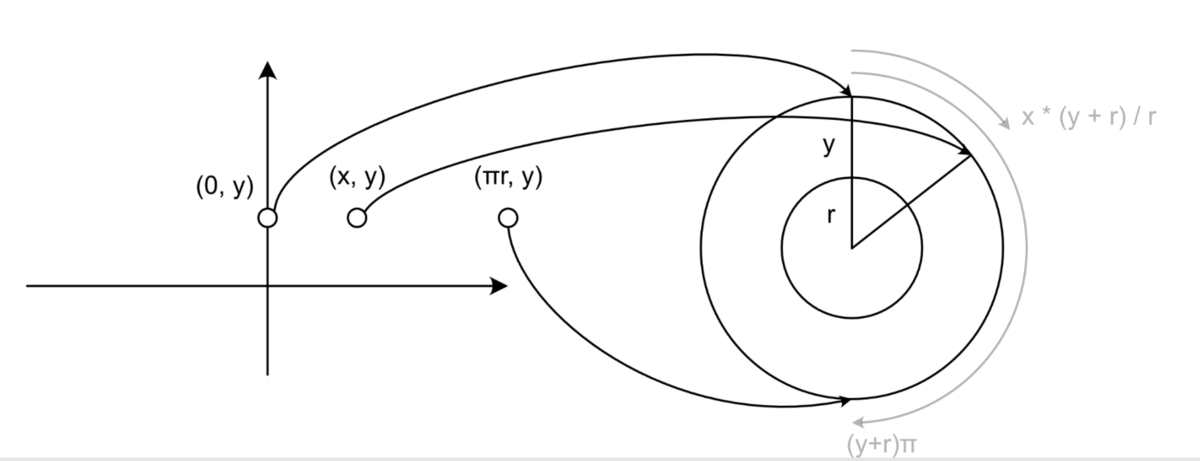
y座標が0ではない場合は変換先の円の半径がになるので、
は半径
の円の真上から円周を
だけ動いたところに変換されて、これは円の真上から
ラジアン回転したところなので同様に
と
を使って計算できることがわかります。
あとはこのような計算を、
- 頂点単位での変換: ここまでの計算を頂点ごとにやる
- メッシュ単位での変換: メッシュの中心など適当な座標を変換して、その座標の周りに頂点を適当に配置し直す
- 書記素単位での変換: StringInfo.GetTextElementEnumeratorを使って1文字列を書記素単位で分割して、メッシュ単位の変換と同じような変換をする
として、TextMeshProUGUIやTMP_TextのGenerateTextMeshをオーバーライドして実装すればやりたいことができます。詳細は冒頭に貼ったリンクを見てください。
結果
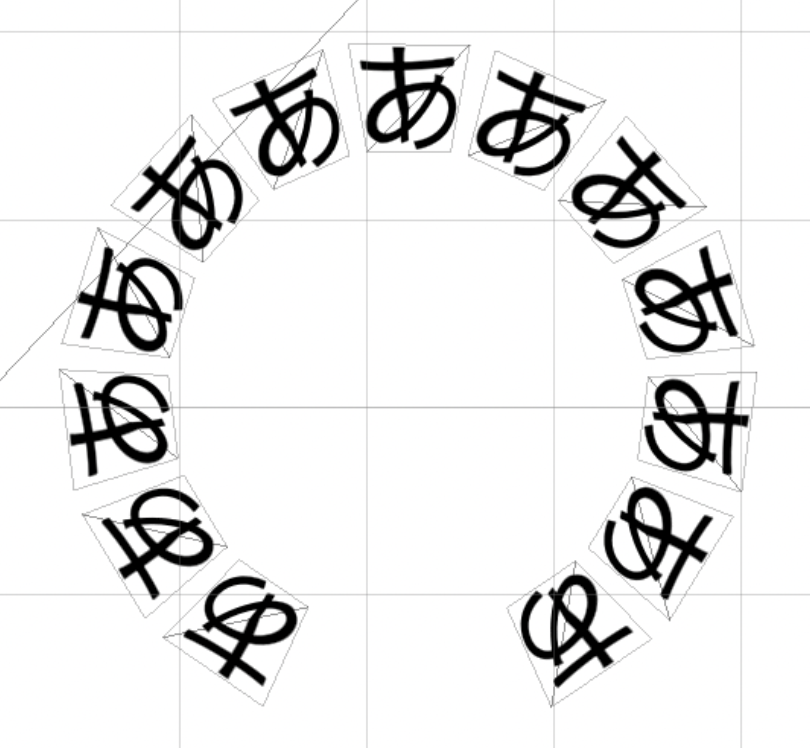
まず頂点単位の変換を見てみます。y座標が大きいほど引き伸ばされるので当然ですが、文字の形が崩れていることが確認できます。
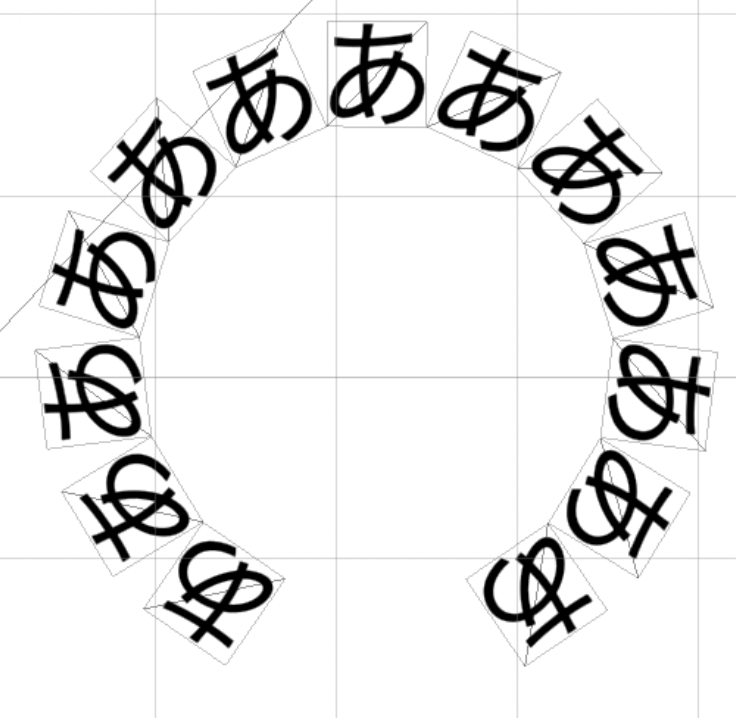
次にメッシュ単位での変換を見てみます。
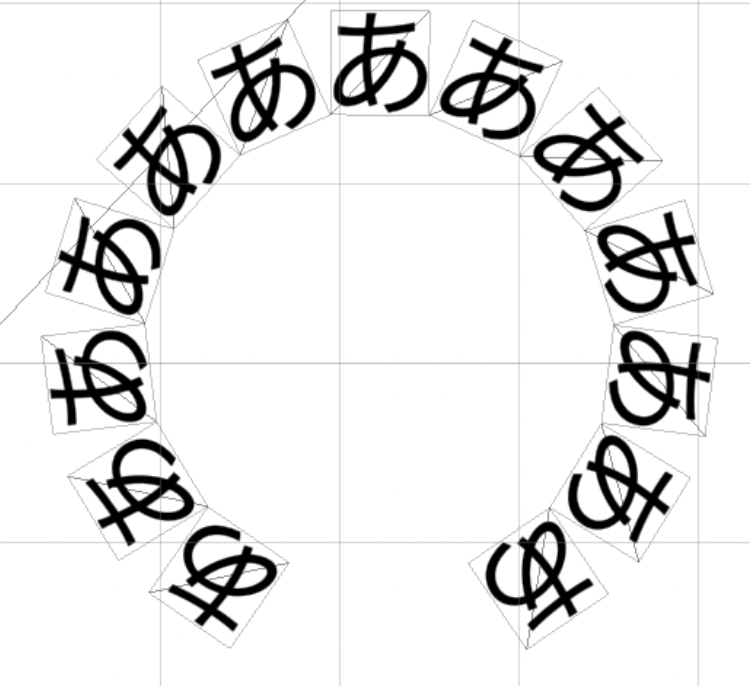
最後に書記素単位での変換を見てみます。
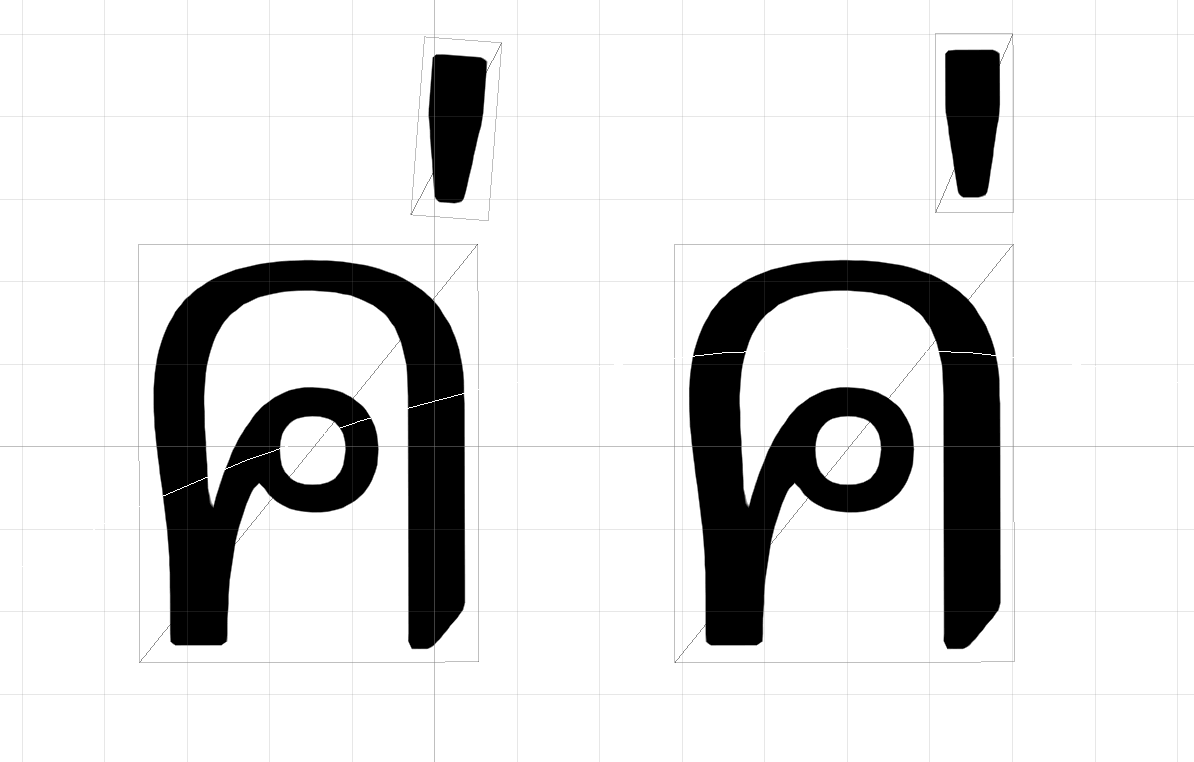
日本語では後ろの2つはどちらもうまく変換されていて違いはないように見えると思いますが、タイ文字のように複数のメッシュを組み合わせて描画される文字では違いがあります。タイ文字を入力して拡大してみると、以下のようにメッシュ単位での変換だと微妙に記号がズレることが確認できます。
最後に
TextMesh Proでテキストを円形に配置する方法について紹介しました。
- GetTextElementEnumeratorは.NET 5以前では正しく分解してくれない場合があります(https://learn.microsoft.com/ja-jp/dotnet/core/compatibility/globalization/5.0/uax29-compliant-grapheme-enumeration)。正しく分解されない文字がある場合は異なる方法を検討する必要があります。↩