SREチームの池田です。 Redshiftが大好きなバケツアイコンの人です。
先日、Aurora MySQL と RedshiftのZero-ETL integrationがGA(Generally Available、一般提供開始)しました。 aws.amazon.com
この記事は、早速Zero-ETL integrationの実戦投入を試してみたという内容です。
なお、この記事は失敗事例になりますが、Zero-ETL integrationはとても素晴らしい機能ですので、皆様も是非お使いください。
はじめに
Zero-ETL integrationは、Aurora MySQLのデータをニアリアルタイムでRedshiftに同期してくれる素晴らしい機能です。
マネージメントコンソールから数ステップでAurora MySQLの中の すべてのテーブルを Redshiftに同期してくれます。
今回、このZero-ETL integrationを早速使ってみたという内容になります。
どのようなAurora MySQLを対象にしたかというと、次のようなSQLの結果が返ってくるClusterを対象にしました。
MySQL [(none)]> SELECT COUNT(DISTINCT table_schema) as schema_count, COUNT(*) as table_count FROM information_schema.tables where table_schema not in ('mysql', 'information_schema'); +--------------+-------------+ | schema_count | table_count | +--------------+-------------+ | 305 | 11103 | +--------------+-------------+ 1 row in set (0.128 sec) MySQL [(none)]>
このような結果が返ってくるAurora MySQLの内容を Redshiftの ra3.xlplus のシングルノードで運用されてるProvisioned Clusterに同期しました。
もし、ここまでで、今回の内容のオチがわかったのならば、貴方はRedshiftに関して熟知していることでしょう。
さて、実際にZero-ETL integrationをした結果、一体どうなるのでしょうか。
Zero-ETL integration自体は問題なく作成できます。
GAになったばかりの新機能。もちろん、prodの本番環境で試すのは危険です。
そこで、まずはdev環境で実用してみようとおもい、意気揚々と dev-aurora という名前のZero-ETL integrationを作成しました。

流石にテーブル数が多いのか、作成自体に30分程かかりましたが、無事に作成できました。 そして、Query Editor v2 でRedshiftの中身を確認してみると、次の図のようになりました。
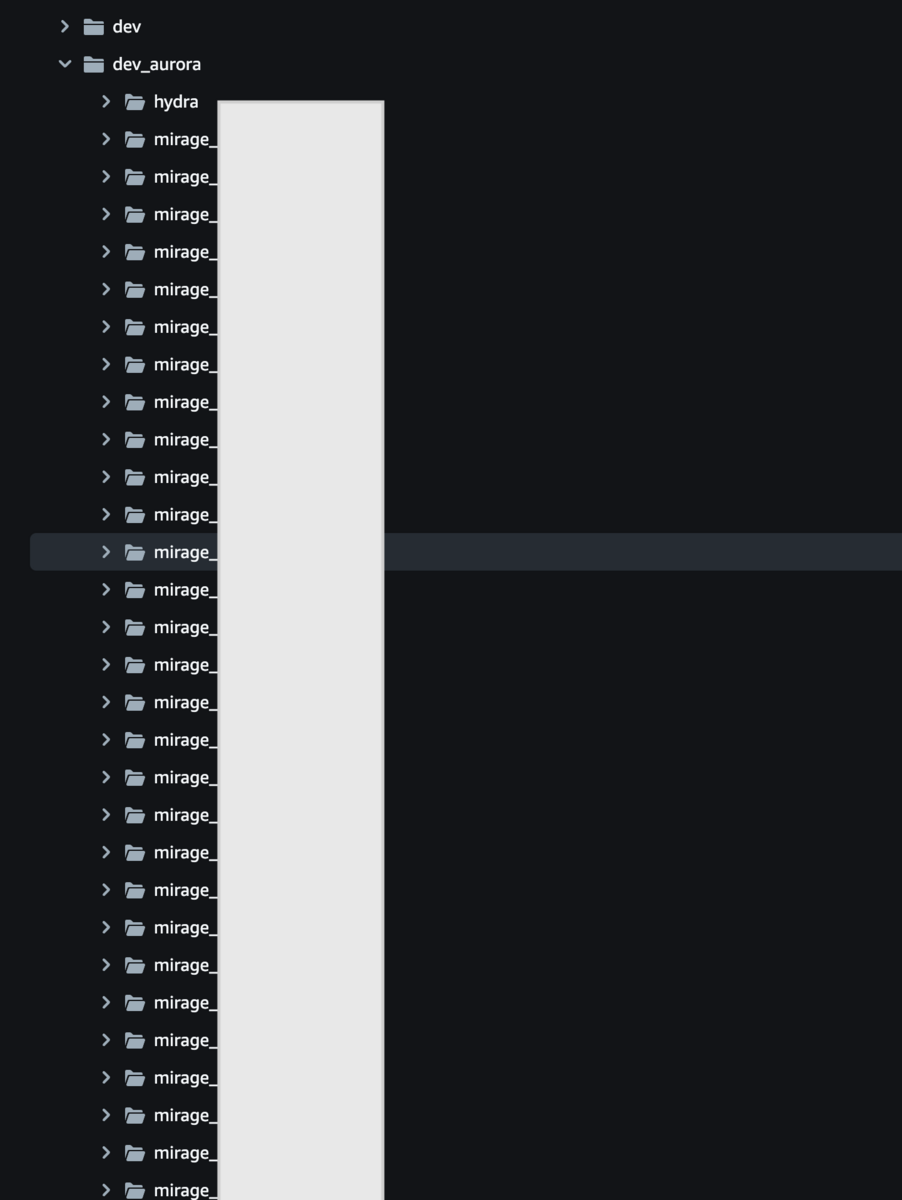
このように、mirage_ というプレフィックスのスキーマがたくさん作成されて、テーブルも順次作成されているようです。
Zero-ETL inegrationでは、 <zero-etlで指定したdb名>.<mysqlのdb名>.<mysqlのtable名> という形で同期されるようです。
ここで、同期されているテーブルについて補足説明します。
このプロダクトでは、以前、当Tech Blogで紹介した mirage-ecs という仕組みを使い、開発環境をたくさん立てています。
そして、開発環境のAurora MySQLには mirage_<環境名>__<マイクロサービス名> という命名規則でデータベースが作成されています。
このプロダクトでは、たくさんの環境を作ってしっかりと検証しながら開発してるため、多くのmirage環境のデータが残っているので、このようにmirage_ というプレフィックスのMySQLデータベースが存在している状態になっています。
そして、そのMySQLを同期した結果が、大量のRedshift上のスキーマーとテーブルになります。
順調に同期されているようなので、しばらく様子をみつつQuickSightからデータを見ようとしたとき異変が起きました。
あれ? Redshiftの様子が...
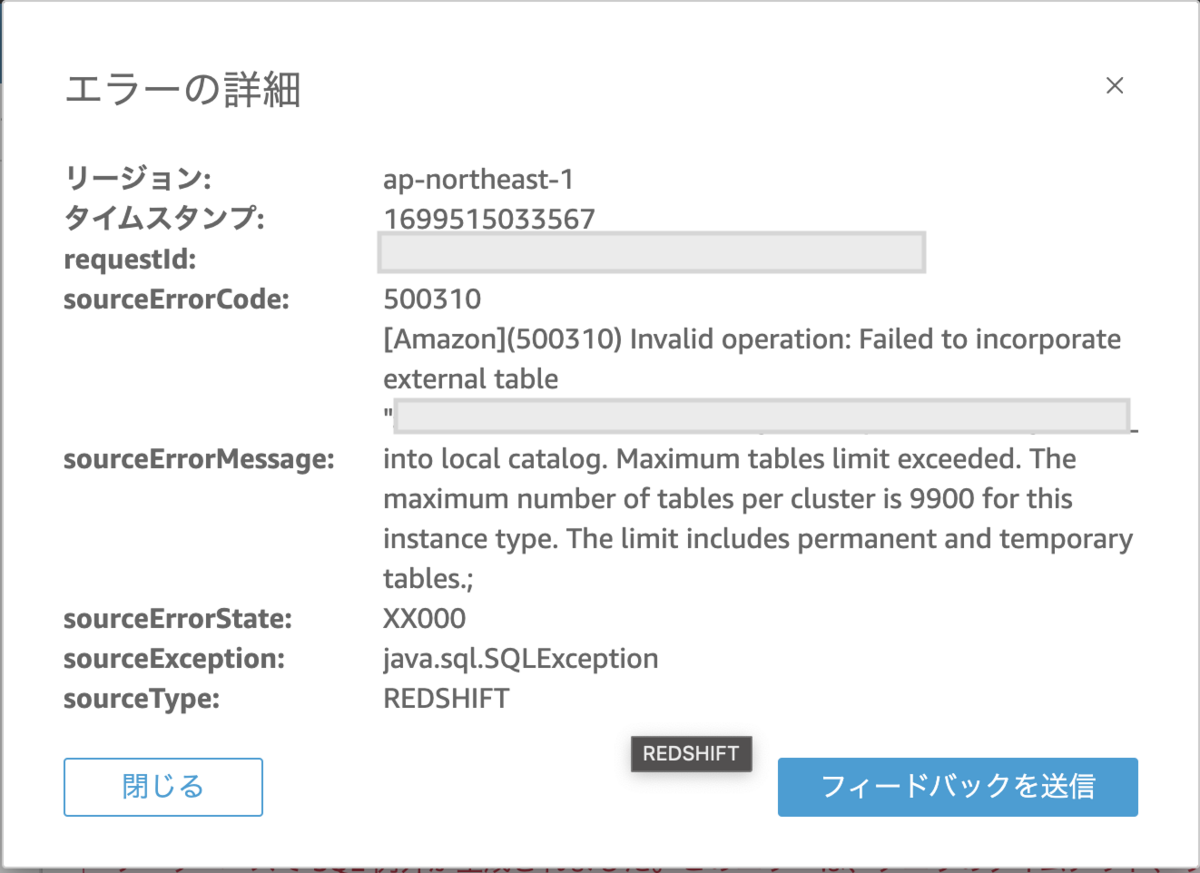
QuickSightでZero-ETL integrationで同期しているテーブルとは別のテーブルを見ようとしたとき、次のようなエラーが発生しました。
Zero-ETL integrationのメトリックの方も見てみると次のようになってました。
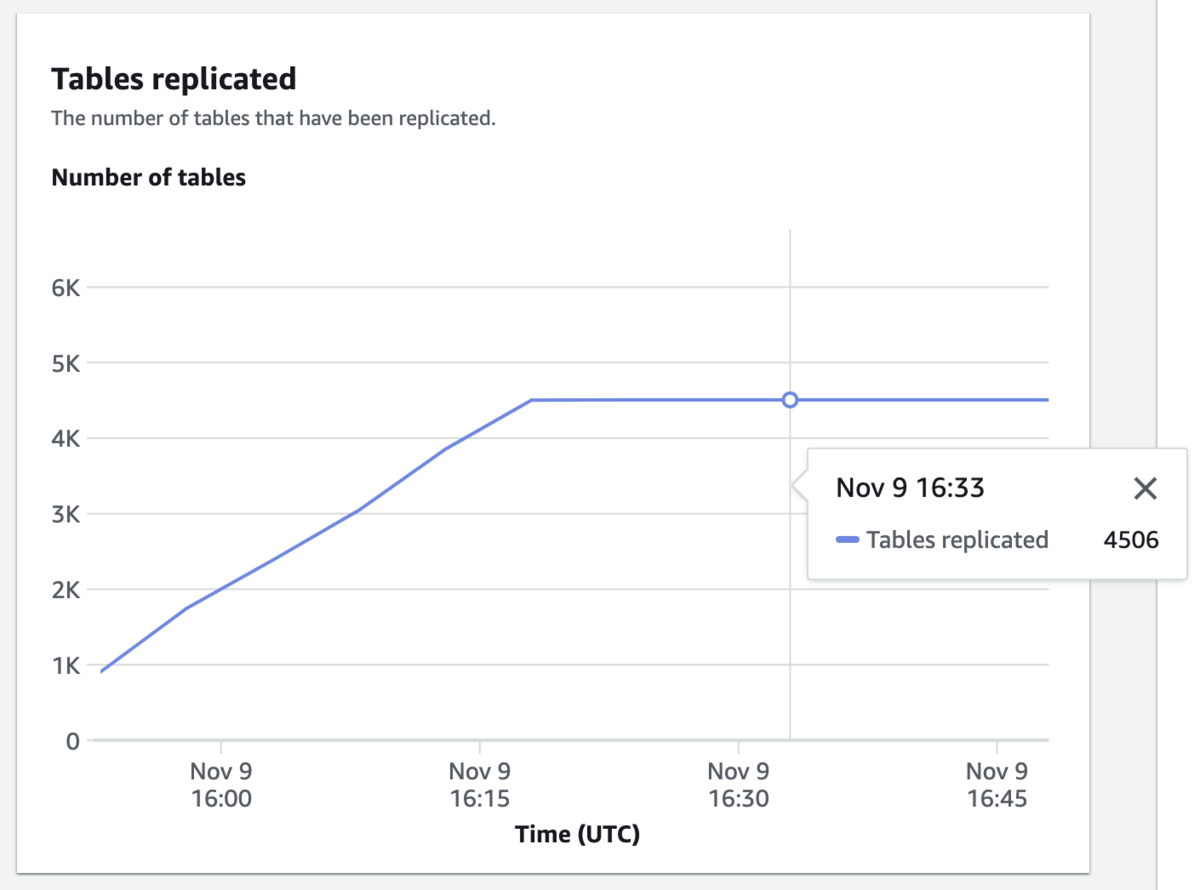
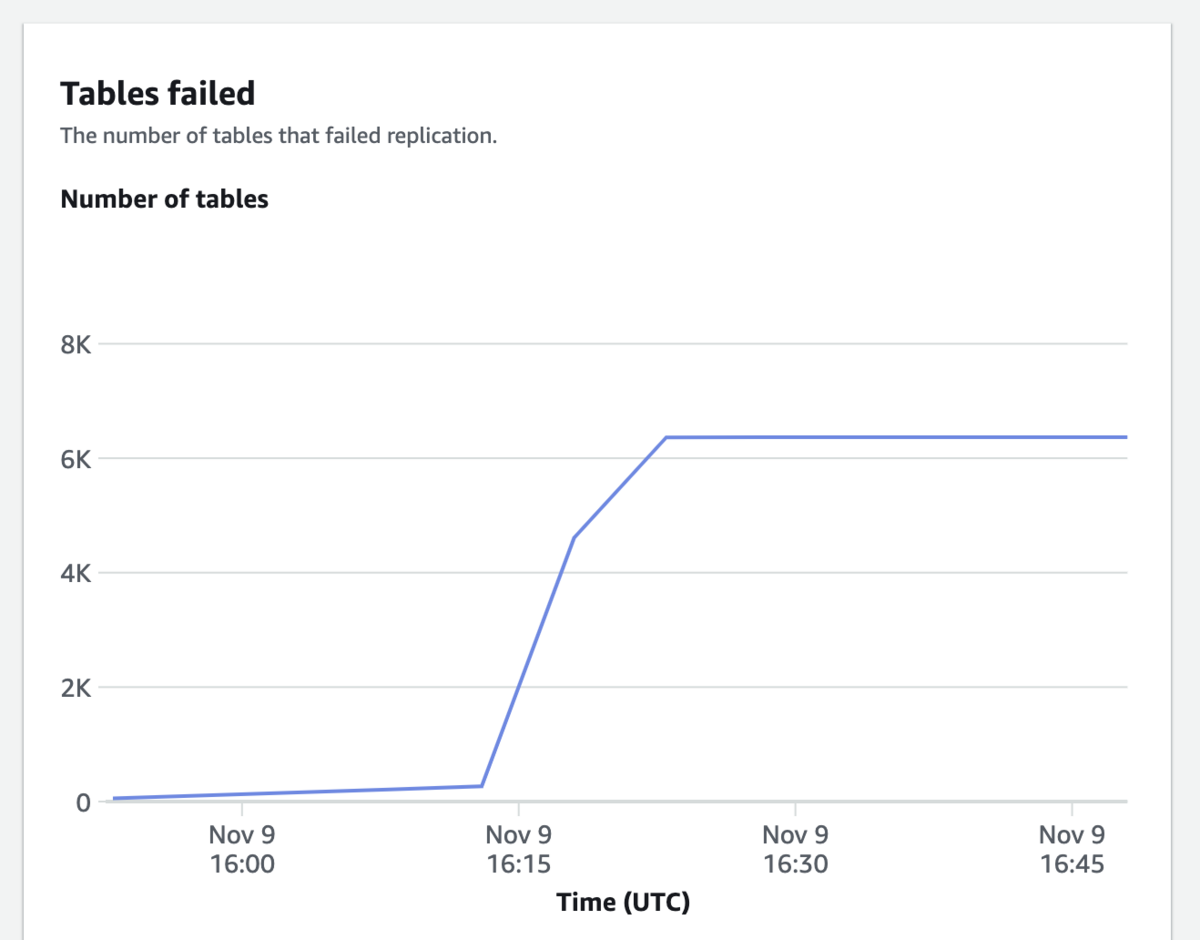
見事に途中でテーブルの同期が止まっています。 これはどういうことかと言うと、次のドキュメントを読むと疑問が解決します。
Tables for xlplus cluster node type with a single-node cluster. 9,900 The maximum number of tables for the xlplus cluster node type with a single-node cluster. This limit includes permanent tables, temporary tables, datashare tables, and materialized views. External tables are counted as temporary tables. Temporary tables include user-defined temporary tables and temporary tables created by Amazon Redshift during query processing or system maintenance. Views and system tables aren't included in this limit.
Redshiftの ra3.xlplus のシングルノードの場合、テーブル数は9900件が上限で、その上限に引っかかりました。
このRedshiftでは、既存ワークロードでテンポラリテーブル等も含めて、5500テーブルほど存在するときがあり、4400テーブルほどZero-ETL integrationで同期した後に、上限に当たって同期が失敗してしまいました。
同期が成功している約4400テーブルには継続的に最新のデータが届いているようでしたので、その点に関してZero-ETL integrationすごい!となりました。
しかし、流石にコレでは実用できないので一旦Zero-ETL integrationを削除して、同期されたdatabaseを削除しました。
ということで、タイトル回収『 Zero-ETL integrationの実用を試みた。 しかし、Aurora MySQLの中身のテーブルが多すぎて失敗した。』でした。
これからどうするのが良いのか?
繰り返しになりますが、Zero-ETL integarationはとても素晴らしい機能ので、積極的に使っていきたいです。 そのために、テーブル数の問題をどうにかする必要があります。その問題を解決する策として。
- 現在アクティブではないmirageの環境のデータを定期的に消す。
- 現在参照されていないRedshiftのデータマートや記録用に保持しているデータをS3にUnloadして、Redshiftから削除する。
- Redshiftのノード数を増やす。 (ノードをmultiノードにすると20,000)まで増える。
- Instanceタイプを大きくする。 (ra3.4xlargeにすると200,000)まで増える。
- 一部の独立性の高いデータをRedshift Serverlessに分割して配置する。
などが考えられます。 コストを据え置きで考えるならば、最初の2案から手を付けるのが良いと思っています。 この機会に、開発用Aurora MySQLとRedshift Clusterのデータのお掃除してから、再度Zero-ETL integarationを使おうと思っています。
また、Zero-ETL integrationのPreviewの時にも、同期するテーブルをフィルタする機能の要望はしています。 この記事が公開される頃にはサポートケースでも要望をすると思いますので、追加機能とかで今回の問題が別の形で解決できることも少し期待してます。