Lobiチームの長田です。
あらゆるWebサービスがそうであるように、Lobiでも日々大量のログが出力されています。 今回はこのログをどのように集約・解析しているかを紹介します。
TL;DR
- アクセスログ・アプリログなど、毎秒10000行以上のログが生成されている
- Fluentdを使用しログを集約
- consul serviceを利用した集約サーバーの冗長化
- ログ中のイベント検知・集約にはNorikraを使用
- アクセスログの各種解析にはAmazon Redshiftを利用
ログの集約
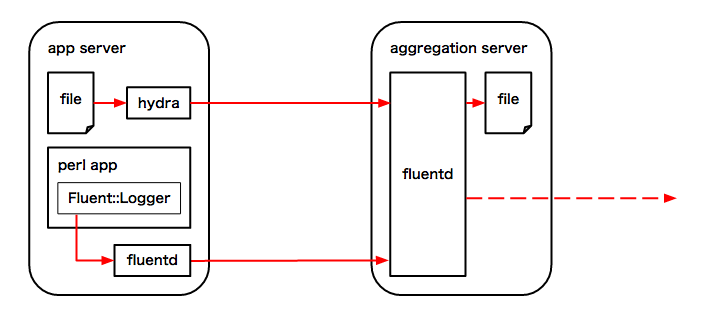
ログ収集エージェント
Lobiではログの集約にFluentdを利用しています。
ログファイルの集約にはfluent-agent-hydraを、Perlアプリケーション内からのログ送信にはFluent::Loggerモジュールをそれぞれ使用しています。
- fujiwara/fluent-agent-hydra: A Fluentd log agent.
- Fluent::Logger - A structured event logger for Fluent - metacpan.org
fluent-agent-hydraはGo言語で書かれたログ収集エージェントです。 Fluentdよりも高速・低リソースで動作します。 詳しくはfluent-agent-hydraのベンチマークディレクトリを参照して下さい。
同じくFluentdの代わりとなるエージェントとしてはPerl製のfluent-agent-liteが有名ですが、 これに対してfluent-agent-hydraはビルド済みのバイナリを配置するだけでセットアップが完了するというメリットがあります。
Fluent::LoggerからはPerlアプリケーションから同ホストのFluentdにログを送信、 更にそこからforwardしてログ集約サーバーのFluentdに送信しています。 この仕組はファイルとして保存されるアクセスログよりも粒度の細かいログを記録する場合に使用します。
ログ集約サーバーの冗長化
Lobiでは現在計4台のログ集約サーバーが稼働しており、それぞれにFluentdが起動しています。 各集約サーバーで集約されたログは1時間単位でファイルとして保存され、 最終的にはAmazon S3にアップロードされます。
各ホストのfluent-agent-hydra、Fluntedからの送信先はconsul service にログ集約サーバーを登録し、それをconsulが提供するDNS機能で名前解決することで決定しています。 consulによるログ集約サーバーのヘルスチェックが失敗した場合は名前解決の対象からは除外されるため、 常に正常稼働しているサーバーにログを送信することができます。 送信中にログ集約サーバーがダウンした場合はFluentdが再送処理を行うためログの集約漏れが発生することはありません。 Fluent::Loggerから直接ログ集約サーバーのFluentdにログ送信を行わないのはこの再送処理を利用するためです。
consulのDNSで送信先を決定する手法には、
- ログ集約サーバーの切り離しをconsul maintだけで行える
- ログ集約サーバーを追加する際にはconsul serviceの追加のみでよく、Fluentdの設定変更は不要
などのメリットもあります。
集約したログファイルのtail
集約サーバーが複数あることで冗長化されているのは安心感があるのですが、 ログファイルが複数のサーバーに分散するため「ちょっとログファイルをtailする」といった操作が行えません。 本番環境での動作を確認したい場合、これでは不便です。
この問題を解消するために、nsshというツールを使用しています。
nsshは複数のサーバーに対してssh経由でコマンド発行を行い、出力をまとめて表示するツールです。 たとえば全ての集約サーバーを対象に以下のようなコマンドを発行すれば、 全てのログに対してまとめてtailをかけることができます。
nssh -t host1 -t host2 -t ... tail -F /var/log/aggregated/api.log
毎回ホスト名を書くのは手間なので、 実際にはconsul membersと連携するラッパースクリプトを通して nsshコマンドを使用しています。
アクセスログの解析
Norikra
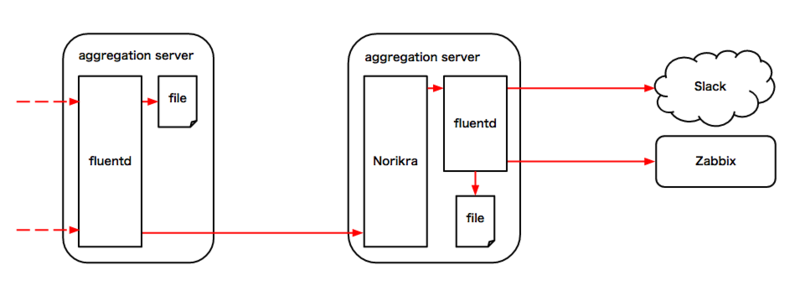
NorikraはSQLでログストリームを処理することができるアプリケーションです。
LobiではNorikraを以下のような各種イベントの検知や、
- HTTPリクエスト処理時に発生したエラー
- バックグラウンドで動作しているworkerプロセスのエラー
- 不自然なチャットメッセージ連投
- 不自然な連続アカウント作成
- DoS攻撃
集計処理に利用しています。
- HTTPリクエストステータスコード別集計
Lobiで生成されるログのほぼ全てがNorikraに渡されており、 その10000行/秒のログをNorikraのプロセスひとつで処理しています(動作ホストはAmazon EC2のm4.2xlarge)。
加工されたログストリームは、専用のFluentdが動作しているサーバーに再度送信されます。 そこで必要な物はファイルに保存され、蓄積・監視が必要な値はzabbixに送信され、迅速な対応が必要な物はSlack等に通知を行います。
以下の例ではアプリケーションのログを1分単位でクエリし、 500番台のエラーが現れたらSlackに通知しています。
# Norikra query SELECT 'notification' AS host, 'app_status_5xx' AS title, 'warn' AS level, count(*) AS count, last(_hostname) AS _hostname, last(message) AS message FROM app.win:time_batch(1 min) WHERE message LIKE '%status:5%'
# Fluentd conf <match norikra.notification.**> type slack webhook_url https://hooks.slack.com/services/***/****** parse none channel lobi username nuko message_keys level,title,count,_hostname,message message ":%s: %s count:%s %s %s" flush_interval 1s </match>
HTTPリクエストのステータスコード集計は、以前はCounter系のFluent Pluginを組み合わせて実現していましたが、
- ログ流量増加に伴い集計処理の負荷に耐えられなくなった
- 設定変更には設定ファイルの変更とfluentdの再起動が必要で、本番環境のデータを用いた試行錯誤が難しかった
などの理由からNorikra導入に至りました。 特に後者については、ちょっとした集計方法の改善や実験的な値取得がWebコンソール上から手軽に行えるため大変重宝しています。 もちろんNorikraで定常的に使用するクエリはコードとしてリポジトリ管理下に置き、誤操作などでクエリが失われてもすぐに復旧できるようになっています。
Amazon Redshift
DAU(Daily Active Users: 1日のアクティブユーザー数)の算出やユーザーの動向調査など、アクセスログの解析が必要になる場合は多々あります。 Lobiでは全てのアクセスログをAmazon Redshiftに投入し、それをクエリすることで解析を行っています。
Redshiftを使用する前はファイルとして保存した圧縮しても数GBあるアクセスログを、 1行ずつ走査して、パースして、メモリ上に中間結果を保持しつつ各項目を集計する、ということを行なっていました。 当然この処理には非常に長い時間とマシンパワーが必要で、末期には午前2時に始めた解析処理が昼ごろにようやく完了する状態でした。
アクセスログをRedshiftに投入し、クエリで集計結果を得るようにしてからは 1時間程度で同等の解析処理を行うことができています。
Redshiftへのログ投入はRinを使用しています。
15分おきに最新のログが投入されるよう設定しているため、 たとえば本番反映したAPI軽量化施策の効果を十数分後には集計結果として得られるようになっています。
Rinについては以下を参照下さい。
また、以前のtech.kayacの記事でも触れていますので、そちらも合わせてご覧下さい。
おわり
次回はAngularJSを使用しているLobi Web版のSEOについて紹介します。